
Las universidades de investigación que realizan operaciones a gran escala en inteligencia artificial (IA) y computación de alto rendimiento (HPC) se enfrentan a numerosos desafíos en su infraestructura, lo que obstaculiza la innovación y retrasa los resultados de sus investigaciones. Los tradicionales clústeres locales de HPC presentan ciclos largos de adquisición de GPU, límites de escalado rígidos y requisitos de mantenimiento complejos, lo que restringe la capacidad de los investigadores para trabajar de manera ágil en tareas de IA, como el procesamiento de lenguaje natural, la visión por computadora y la formación de modelos fundamentales.
Amazon SageMaker HyperPod surge como una solución que alivia la carga operativa involucrada en la construcción de modelos de IA, permitiendo una rápida escalabilidad en las tareas de desarrollo de modelos, incluidos el entrenamiento, la optimización y la inferencia, sobre un clúster que puede incluir cientos o miles de aceleradores de IA, como las GPU de NVIDIA H100 o A100.
Recientemente, una universidad de investigación implementó SageMaker HyperPod para acelerar su investigación en IA, utilizando particiones dinámicas de SLURM, gestión fina de recursos de GPU, seguimiento de costos computacionales y balanceo de carga de nodos de acceso, todo integrado en el entorno de SageMaker HyperPod. Este enfoque permite a los investigadores acceder a las herramientas necesarias sin los contratiempos asociados a la gestión de infraestructuras tradicionales.
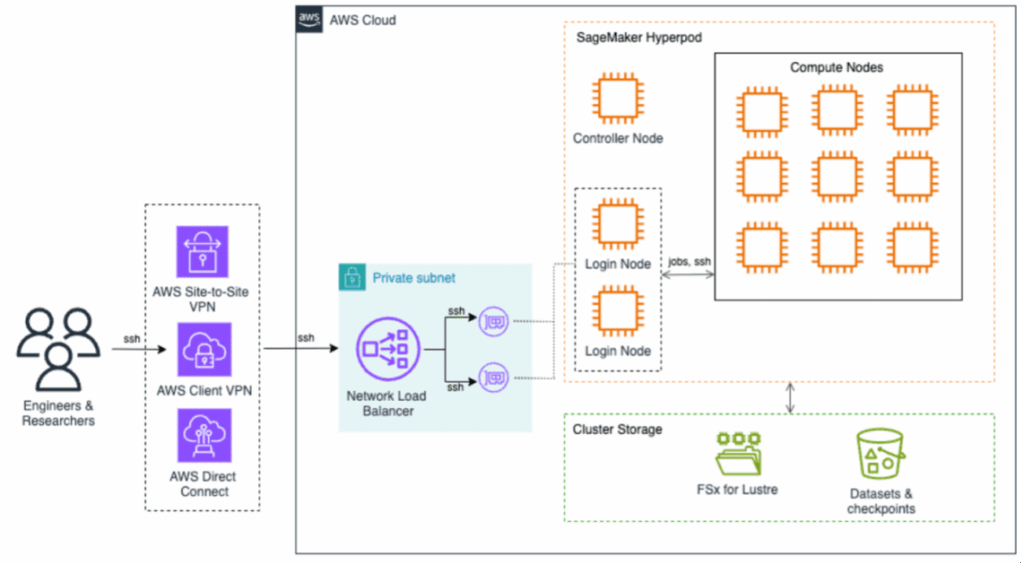
La arquitectura de SageMaker HyperPod está diseñada para respaldar operaciones de aprendizaje automático a gran escala, con la infraestructura gestionada completamente por AWS, lo que elimina la sobrecarga operativa mientras se garantiza un alto nivel de seguridad y rendimiento. Los usuarios pueden acceder a SageMaker HyperPod utilizando diversas opciones de conexión seguras que optimizan el tráfico y mejoran la interacción con el clúster.
La infraestructura de almacenamiento se basa en dos componentes principales: Amazon FSx para Lustre, que ofrece capacidades de sistemas de archivos de alto rendimiento, y Amazon S3, destinado al almacenamiento seguro de conjuntos de datos y puntos de control, asegurando así un acceso rápido a los datos necesarios para el entrenamiento de modelos.
El proceso de implementación se llevó a cabo en varias etapas, comenzando con la configuración de AWS y la infraestructura necesaria, seguido por la personalización de la configuración del clúster SLURM para adaptarse a las necesidades de investigación del departamento. Con la habilitación de la configuración de recursos genéricos (GRES), se logró un uso más eficiente al permitir que múltiples usuarios accedieran a las GPUs sin contención.
Para controlar el uso y los costos, cada recurso del SageMaker HyperPod fue etiquetado con un identificador único, lo que permitió un seguimiento mensual del gasto a través de AWS Budgets y AWS Cost Explorer, asegurando así un uso eficiente y predecible de los recursos. Además, se implementó un sistema de balanceo de carga para los nodos de acceso, optimizando el acceso a los recursos por parte de varios usuarios simultáneamente.
Finalmente, se llevó a cabo la integración con un sistema de Active Directory para facilitar el acceso seguro para los investigadores, garantizando que se mantuviera un control unificado sobre las identidades y privilegios de los usuarios.
Con estas implementaciones y ajustes, el uso de SageMaker HyperPod promete una transformación significativa en la computación de investigación, permitiendo a las instituciones académicas acelerar la innovación en IA y enfocarse en sus objetivos científicos, en lugar de lidiar con los retos de las infraestructuras tradicionales.
vía: AWS machine learning blog