
En el mundo actual, las aplicaciones de inteligencia artificial moderna exigen respuestas rápidas y rentables de los modelos de lenguaje grande (LLM), particularmente en el manejo de documentos extensos y conversaciones prolongadas. Sin embargo, el proceso de inferencia de LLM puede volverse cada vez más lento y costoso a medida que aumenta la longitud del contexto, ya que la latencia crece exponencialmente y los costos se incrementan con cada interacción.
Un desafío clave en la inferencia de LLM es la necesidad de recalcular los mecanismos de atención para los tokens previos al generar cada nuevo token. Este proceso introduce una considerable sobrecarga computacional y alta latencia, especialmente en secuencias largas. La solución al atasco de latencia en la inferencia de LLMs se conoce como almacenamiento en caché de clave-valor (KV en inglés), que permite almacenar y reutilizar vectores de atención de computaciones previas, reduciendo así la latencia de inferencia y el tiempo hasta el primer token. La implementación de un enrutamiento inteligente en LLMs ofrece la posibilidad de enviar solicitudes con indicaciones compartidas a la misma instancia de inferencia, maximizando la eficiencia del caché KV. Esto significa que una nueva solicitud se dirige a una instancia que ya ha procesado el mismo prefijo, permitiendo reutilizar los datos almacenados en caché para acelerar el procesamiento.
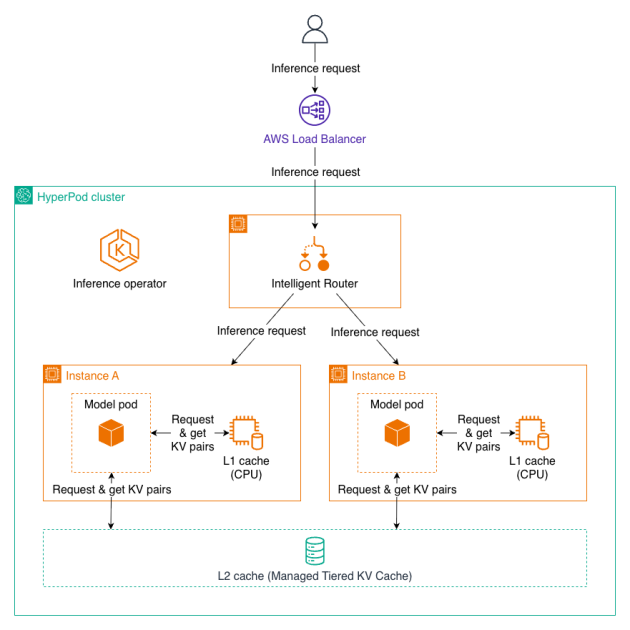
Hoy se ha anunciado que Amazon SageMaker HyperPod ahora soporta capacidades de Gestión de Caché de KV en Niveles y Enrutamiento Inteligente a través del Operador de Inferencia de HyperPod. Estas nuevas capacidades prometen mejoras significativas en el rendimiento para las cargas de trabajo de inferencia de LLM, reduciendo el tiempo hasta el primer token en hasta un 40%, aumentando el rendimiento y disminuyendo costos computacionales en hasta un 25% para contextos largos y conversaciones de múltiples turnos.
El sistema de cacheo eficiente combinado con un enrutamiento inteligente maximiza los aciertos del caché entre los trabajadores, alcanzando un mayor rendimiento y menores costos en las implementaciones de modelos. Estas características son especialmente beneficiosas en aplicaciones que procesan documentos largos donde se hace referencia al mismo contexto, así como en conversaciones de múltiples turnos que requieren mantener el contexto de intercambios anteriores de manera eficiente.
Por ejemplo, equipos legales que analizan contratos de 200 páginas ahora pueden recibir respuestas instantáneas a preguntas de seguimiento en lugar de esperar más de 5 segundos por consulta. Los chatbots de atención sanitaria pueden mantener un flujo de conversación natural en diálogos con más de 20 turnos, y los sistemas de atención al cliente pueden procesar millones de solicitudes diarias con un mejor rendimiento y menores costos de infraestructura. Estas optimizaciones hacen que el análisis de documentos, las conversaciones de múltiples turnos y las aplicaciones de inferencia de alto rendimiento sean viables económicamente a gran escala.
Las nuevas características incluyen la Gestión de Caché de KV en Niveles, que automatiza el manejo de los estados de atención a través de la memoria CPU (L1) y el almacenamiento tiered (L2), y el Enrutamiento Inteligente, que proporciona estrategias como el enrutamiento consciente del prefijo y el enrutamiento KV-consciente para maximizar los aciertos del caché. Además, incluye integración de observabilidad para realizar seguimiento de las métricas y los registros en Amazon Managed Grafana.
La implementación de estos avances implica crear un clúster de HyperPod con Amazon EKS como orquestador, para luego habilitar la Gestión de Caché y el Enrutamiento Inteligente en la configuración de los endpoints de inferencia. Con estos nuevos desarrollos, Amazon sigue posicionándose como un líder en la provisión de soluciones de inteligencia artificial escalables y accesibles para el negocio global.
vía: AWS machine learning blog