
Amazon ha introducido una solución integral para la clasificación automática de texto utilizando la capacidad de inferencia por lotes de Amazon Bedrock y el modelo Claude Haiku de Anthropic. Esta innovación resulta especialmente relevante para organizaciones que enfrentan el desafío diario de manejar grandes volúmenes de datos, como las conversaciones en los centros de atención al cliente de agencias de viajes. La inferencia por lotes de Amazon Bedrock, que ofrece un descuento del 50% respecto a los precios bajo demanda, permite llevar a cabo esta tarea de manera eficiente y económica.
La necesidad de clasificaciones precisas y rápidas impacta en diversas industrias, desde agencias de viajes hasta departamentos financieros. Empresas que clasifican consultas de clientes, analizan oportunidades de venta perdidas o gestionan facturas pueden beneficiarse considerablemente de la automatización. Sin embargo, la transición hacia sistemas automatizados no está exenta de desafíos, que incluyen el manejo de grandes volúmenes de datos textuales mientras se garantiza la precisión en los resultados.
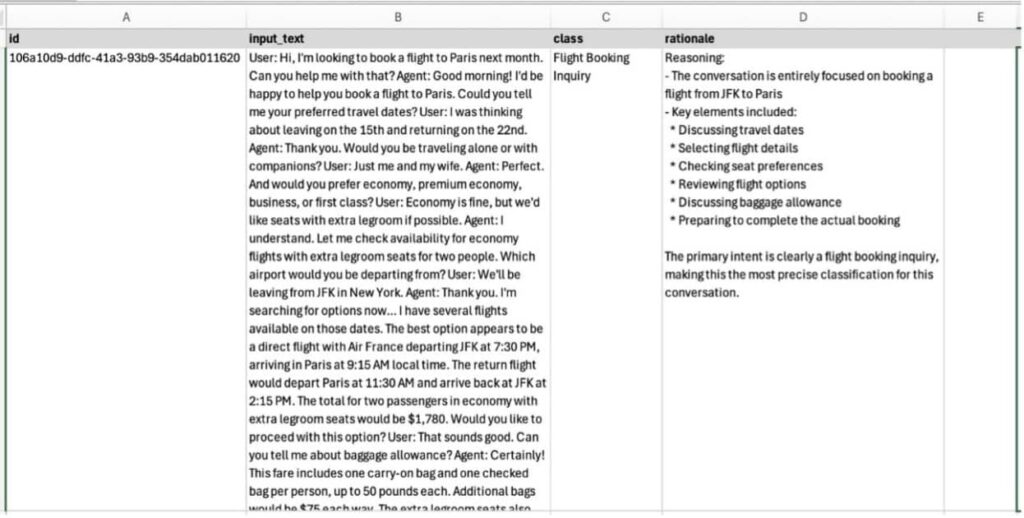
Para abordar este problema, se utilizó un conjunto de datos sintéticos de conversaciones de atención al cliente, generados con el modelo Claude 3.7 Sonnet. Las conversaciones abarcan diversos temas, como consultas sobre reservas de vuelos, cambios en reservas y solicitudes de cancelación. Este enfoque no solo ayuda a proteger la privacidad del usuario, sino que también proporciona un marco estructurado para la clasificación.
La arquitectura de la solución es escalable y se basa en un diseño sin servidor y orientado a eventos. Una vez que llegan nuevas solicitudes de clasificación a un bucket de Amazon S3, el sistema utiliza Amazon Bedrock para procesar y clasificar contenido en gran cantidad, minimizando la necesidad de supervisión manual. Este proceso abarca desde la preparación de datos hasta la inferencia por lotes y la organización de resultados en formatos accesibles como CSV, JSON o XLSX.
Al probar la solución con 1.190 conversaciones sintéticas, se lograron tiempos de procesamiento consistentes de 11 a 12 minutos por lote, con una precisión del 100%. Esto muestra la efectividad de la solución, que también se diseñó teniendo en cuenta buenas prácticas de seguridad y mantenimiento de costos.
A pesar de estos éxitos, se identificaron algunas limitaciones, como la necesidad de un tamaño mínimo de lote de 100 clasificaciones y el tiempo de procesamiento que podría variar según la carga de trabajo. Además, se reconoce la importancia de limpiar los recursos de AWS utilizados para evitar costos adicionales.
Con esta evolución tecnológica, empresas de múltiples sectores podrán no solo reducir el tiempo dedicado a tareas manuales, sino también obtener información valiosa a partir de los datos de clasificación, mejorando así su servicio al cliente y optimizando sus operaciones.
vía: AWS machine learning blog