
La formación de modelos de lenguaje de última generación requiere una compleja infraestructura informática distribuida. Un ejemplo es Llama 3 de Meta, que utilizó 16,000 GPUs NVIDIA H100 durante más de 30.84 millones de horas de GPU. Amazon Elastic Kubernetes Service (EKS) es un servicio administrado que simplifica el despliegue, la gestión y la escalabilidad de clústeres de Kubernetes, adecuado para entrenar estos modelos masivos. Para facilitar la configuración de cargas de trabajo distribuidas, AWS ofrece Deep Learning Containers (DLCs) que contienen imágenes preconstruidas y optimizadas para frameworks populares como PyTorch, lo que permite a los equipos lanzar trabajos más rápido y con menos problemas de compatibilidad. A pesar de esto, la configuración de clústeres para grandes cargas de trabajo de entrenamiento no es una tarea sencilla.
Una de las principales dificultades es la configuración de las GPUs en las instancias de Amazon EC2 que se utilizan para el entrenamiento distribuido. Las instancias de EC2 con soporte para GPU se dividen en dos familias: la familia G, indicada para inferencias y entrenamiento más ligero, y la familia P, especializada en trabajos masivos y distribuidos. A pesar de que las instancias G son más asequibles, carecen del ancho de banda elevado y la baja latencia necesarias para escalas extremas. Por otro lado, las instancias P, aunque rápidas, requieren una configuración precisa de la red, el almacenamiento y la topología de las GPUs, lo que aumenta su complejidad operativa y puede ser una fuente de errores.
Para prevenir problemas de configuración en el entrenamiento distribuido con Amazon EKS, se puede seguir un enfoque sistemático que verifique la correcta configuración de los componentes requeridos. Este artículo describe los pasos necesarios para configurar y validar un clúster EKS para el entrenamiento de grandes modelos utilizando DLCs.
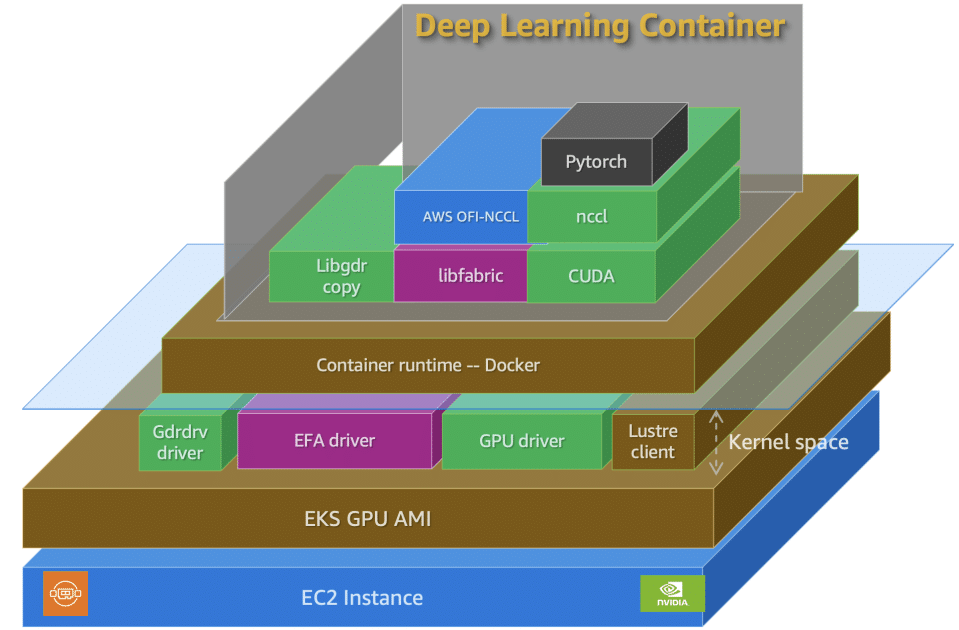
La solución abarca varios pasos, comenzando por la construcción de una imagen Docker con las dependencias requeridas usando un DLC de PyTorch. Posteriormente, se lanza la infraestructura necesaria en un clúster de GPU listo y estable, donde se instalan plugins específicos para dispositivos GPU, soporte de Elastic Fabric Adapter (EFA), y sistemas de almacenamiento persistente. Luego, se realizan chequeos de salud para asegurar que los nodos están listos y correctamente configurados. Finalmente, se lanza un pequeño trabajo de entrenamiento para validar el sistema en su conjunto.
Para llevar a cabo este proceso se recomienda contar con una cuenta de AWS, cuotas de servicio suficientes para instancias G según demanda, y un token de Hugging Face con acceso a Meta Llama 2 7B. Se propone construir una imagen Docker a partir de AWS DLCs, que están optimizadas para la ejecución de frameworks populares como PyTorch en AWS.
Además, se requiere configurar un clúster EKS que incluya un grupo de nodos de sistema y uno de GPU, lo que también implica la instalación de varios complementos de Amazon EKS para la provisión de almacenamiento y la observabilidad del clúster. La configuración final de estos nodos y complementos permite crear un entorno productivo para cargas de trabajo de entrenamiento distribuidas a gran escala.
El proceso de validación de la configuración incluye verificar que los drivers de GPU y la comunicación entre nodos funcionan correctamente, además de ejecutar una carga de trabajo de validación que garantice la integración de la infraestructura. Este enfoque permite a los equipos enfocar sus esfuerzos en la innovación y mejora continua del rendimiento de los modelos en lugar de lidiar con la complejidad de la infraestructura subyacente.
vía: AWS machine learning blog