
Las empresas, especialmente en la industria de seguros, enfrentan desafíos crecientes para procesar grandes volúmenes de datos no estructurados provenientes de diversos formatos, como PDFs, hojas de cálculo, imágenes, videos y archivos de audio. Documentos de reclamación, videos de accidentes, transcripciones de chats o documentos de pólizas contienen información vital a lo largo del ciclo de procesamiento de reclamaciones.
Los métodos tradicionales de preprocesamiento de datos, aunque funcionales, pueden tener limitaciones en precisión y consistencia, lo que afecta la completitud de la extracción de metadatos, la velocidad del flujo de trabajo y la eficacia del uso de datos para obtener información impulsada por inteligencia artificial, como la detección de fraudes o el análisis de riesgos. Para abordar estos problemas, se presenta un sistema de colaboración entre múltiples agentes: un conjunto de agentes especializados en clasificación, conversión, extracción de metadatos y tareas específicas del dominio. Orquestando estos agentes, es posible automatizar la ingesta y transformación de una amplia gama de datos no estructurados y multimodales, mejorando la precisión y habilitando análisis de extremo a extremo.
Para equipos que procesan un volumen pequeño de documentos homogéneos, una configuración de un solo agente puede ser más simple de implementar y suficiente para automatizaciones básicas. Sin embargo, cuando los datos abarcan diversos dominios y formatos, como paquetes de documentos de reclamación o videos de colisiones, una arquitectura de múltiples agentes ofrece ventajas significativas. Los agentes especializados permiten una ingeniería de prompts dirigida, mejor depuración y extracción más precisa, cada uno ajustado a un tipo de dato específico.
A medida que aumenta el volumen y la variedad de información, este diseño modular ofrece una escalabilidad más eficiente, permitiendo la incorporación de nuevos agentes conscientes del dominio o la mejora de prompts individuales y lógica empresarial sin interrumpir la canalización general. El feedback de expertos en el dominio se puede mapear de nuevo a agentes específicos durante la fase de intervención humana, apoyando la mejora continua.
Este enfoque se puede respaldar con Amazon Bedrock, un servicio completamente gestionado que facilita la creación y escalabilidad de aplicaciones de inteligencia artificial generativa utilizando modelos base de empresas líderes. Una funcionalidad poderosa de Amazon Bedrock permite la creación de agentes inteligentes conscientes del dominio, que pueden recuperar contexto de las bases de conocimiento y orquestar tareas en múltiples pasos. Estos agentes proporcionan la flexibilidad necesaria para procesar datos no estructurados a gran escala y pueden evolucionar junto con los flujos de trabajo y datos de la empresa.
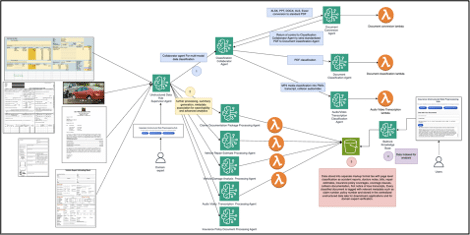
El sistema se presenta como un centro de preprocesamiento de datos no estructurados con características como clasificación de datos entrantes, extracción de metadatos para números de reclamación y fechas, conversión de documentos a formatos uniformes, y validación humana para campos inciertos o faltantes. Los resultados enriquecidos y los metadatos asociados desembocan en un lago de datos no estructurados rico en metadatos, que sienta las bases para la detección de fraudes y análisis avanzado.
El flujo de trabajo de extremo a extremo presenta un agente supervisor en el centro, con agentes de clasificación y conversión ramificándose, incluyendo un paso de intervención humana y Amazon S3 como el destino final del lago de datos no estructurados. La modularidad del sistema permite que cada agente maneje funciones específicas, promoviendo una gestión más escalable y robusta. Con estos avances, se espera reducir significativamente el tiempo de validación humana y mejorar la precisión de la extracción de metadatos, optimizando así el procesamiento de datos. La integración continua de experticia humana en el ciclo de validación asegura que la calidad y la estructura de los datos mejoren con el tiempo.
En conclusión, transformar datos no estructurados en salidas ricas en metadatos permite a las empresas acelerar procesos críticos, como la detección de fraudes, optimizar perfiles de clientes y facilitar decisiones informadas basadas en análisis avanzados. A medida que este sistema de colaboración entre múltiples agentes evoluciona, se espera que reduzca significativamente la necesidad de intervención humana y ofrezca una automatización más completa, consolidando así su papel en el futuro del procesamiento de reclamaciones en el sector asegurador.
vía: AWS machine learning blog