

El 18 de noviembre de 2025, durante varias horas, una parte masiva del tráfico mundial que pasa por Cloudflare empezó a devolver errores HTTP 5xx. Para millones de usuarios fue “solo” que muchas webs dejaron de funcionar. Para equipos de seguridad, SRE y defensores en todo el mundo fue algo mucho más inquietante: el fallo de uno de los nodos centrales de la red, el tipo de pieza que nadie quiere ver caer.
Cloudflare ha publicado un informe técnico detallado en el que confirma que no hubo ciberataque de por medio. La causa fue un fallo lógico en la gestión de configuración de su módulo de Bot Management que acabó tumbando su core proxy. El incidente es especialmente relevante para la comunidad de ciberseguridad porque expone un patrón peligroso: cómo una cadena de errores de permisos, consultas a base de datos y validación insuficiente de ficheros internos puede provocar un evento de impacto global comparable a un ataque de denegación de servicio masivo.
Qué pasó realmente el 18 de noviembre
Según el propio relato de la compañía, todo comenzó a las 11:20 UTC. El sistema de entrega de contenidos y seguridad de Cloudflare empezó a servir errores 5xx de forma masiva. El gráfico interno de la empresa, que suele mostrar una línea casi plana de errores, se convirtió en una montaña con picos recurrentes.
Los síntomas iniciales encajaban con lo que muchos equipos de seguridad han aprendido a temer:
- subida súbita de errores,
- degradación de servicios críticos,
- y problemas incluso en sistemas auxiliares.
Hasta la página pública de estado de Cloudflare, alojada fuera de su infraestructura, llegó a mostrar un error, lo que llevó a parte del equipo a sospechar de un posible ataque coordinado. En paralelo, todavía flotaba el recuerdo reciente de grandes campañas DDoS (como las asociadas a la botnet Aisuru), lo que ayudó a reforzar esa hipótesis.
Sin embargo, el origen estaba dentro de casa. Y muy lejos de los patrones clásicos de intrusión: el detonante fue un cambio aparentemente benigno en los permisos de un clúster de bases de datos ClickHouse.
El “feature file” que dobló su tamaño y colapsó el proxy
El punto crítico del incidente está en el módulo de Bot Management, que asigna una puntuación de probabilidad de “bot” a cada petición que atraviesa la red de Cloudflare. Para funcionar, este módulo depende de un archivo de configuración —el feature file— que describe qué características debe considerar el modelo de machine learning.
Ese fichero se genera automáticamente cada pocos minutos a partir de consultas a ClickHouse y se distribuye a todos los nodos de la red. El objetivo es lógico desde el punto de vista de seguridad: reaccionar rápido a nuevos patrones de tráfico malicioso y ajustar la detección de bots en tiempo casi real.
El problema surgió cuando un cambio en la forma en la que se gestionaban los permisos y la visibilidad de tablas en ClickHouse hizo que una consulta clave empezara a devolver datos duplicados. En vez de listar columnas de un único esquema, la consulta comenzó a incluir también metadatos de tablas subyacentes, multiplicando el número de “features” generadas.
Resultado:
- el feature file prácticamente dobló su tamaño,
- el número de características superó el límite de 200 definido en el módulo,
- y el código responsable de cargarlo lanzó un panic al intentar hacer un
unwrap()sobre un error, sin una ruta de degradación controlada.
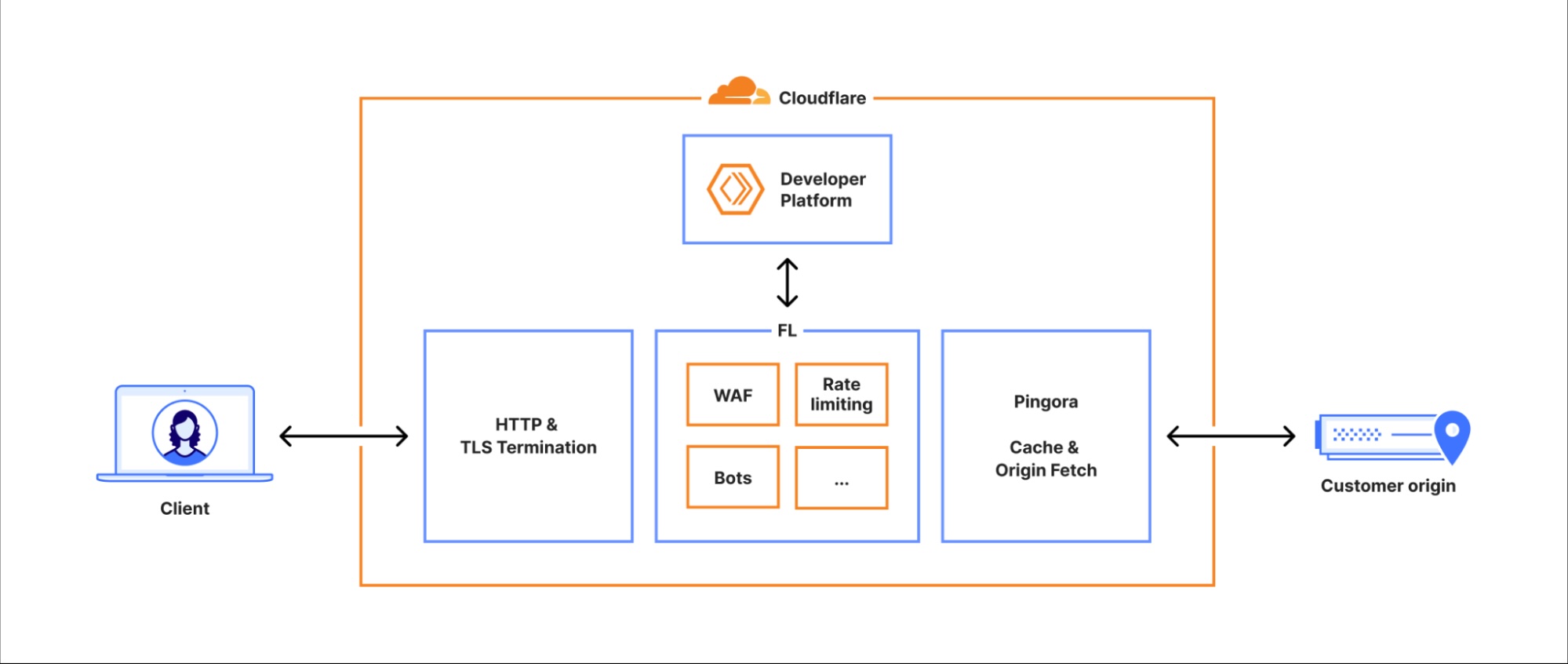
Ese fallo se propagó directamente al proxy central de Cloudflare (FL y su nueva versión FL2). En FL2, utilizado ya por buena parte del tráfico de clientes, el error se traducía en una cascada de respuestas 5xx. En FL, el impacto era distinto: no generaba errores visibles, pero asignaba una puntuación de bot igual a cero a todo el tráfico, lo que podía provocar falsos positivos o negativos según las reglas de cada cliente.
Desde la perspectiva de seguridad, el mensaje es claro: un módulo de protección mal aislado puede convertirse en un punto único de fallo para todo el plano de datos.
Un fallo intermitente que parecía un DDoS
Otro aspecto relevante para la comunidad de seguridad es cómo la naturaleza intermitente del fallo dificultó el diagnóstico. El feature file se regeneraba cada cinco minutos, pero no todos los nodos del clúster ClickHouse se habían actualizado al mismo tiempo.
Eso generó un patrón muy confuso:
- a veces se producía un fichero “bueno” (configuración anterior correcta),
- otras veces un fichero “malo” (duplicado y sobredimensionado),
- y la red oscilaba entre periodos de aparente normalidad y picos de errores masivos.
Desde fuera, y durante parte del análisis interno, el comportamiento se parecía mucho a una ofensiva de denegación de servicio adaptativa: el sistema “caía”, se recuperaba, volvía a fallar, y además coincidía con problemas en la página de estado alojada externamente.
La lección que subrayan muchos expertos: los fallos lógicos internos pueden imitar el patrón de un ciberataque a gran escala, y sin una observabilidad precisa es fácil perder tiempo valioso persiguiendo un fantasma equivocado. El plan de respuesta a incidentes de una organización debe contemplar explícitamente esta posible confusión.
La superficie afectada: CDN, Workers KV, Access y autenticación
El informe de Cloudflare detalla el impacto en varios servicios clave:
- Core CDN y servicios de seguridad
La cara más visible del incidente: usuarios viendo páginas de error 5xx en webs protegidas por Cloudflare, independientemente de si se trataba de pequeños sitios personales o grandes plataformas. - Workers KV
El almacenamiento key-value utilizado por multitud de aplicaciones serverless devolvió niveles anómalamente altos de errores, al depender de la pasarela frontend afectada. Muchos servicios internos y de clientes que confían en KV se vieron degradados. - Cloudflare Access
Los fallos de autenticación fueron generalizados. Quienes ya tenían sesión abierta pudieron seguir accediendo, pero los nuevos intentos chocaban con páginas de error. A nivel de seguridad, es relevante que, según el propio informe, ningún login fallido llegó a pasar al backend protegido: es decir, el “corte” se produjo antes de que el usuario alcanzase la aplicación de destino. - Turnstile y panel de control
El sistema de protección de formularios utilizado en el login del panel de Cloudflare dejó de funcionar correctamente, impidiendo que muchos administradores se autenticaran para gestionar sus configuraciones justo durante la crisis. Una situación delicada para cualquier equipo de seguridad: un incidente grave y acceso limitado al control plane. - Email Security
El servicio de filtrado de correo siguió procesando mensajes, pero perdió temporalmente acceso a una fuente de reputación IP, reduciendo la eficacia de algunas detecciones. No se observaron impactos críticos, aunque sí una degradación en la precisión de reglas avanzadas.
Además, la propia infraestructura de observabilidad y debugging de Cloudflare contribuyó a la presión sobre el sistema: al intentar enriquecer cada error con más información, los procesos de monitorización consumieron más CPU, aumentando la latencia global.
Patrones de fallo que deberían preocupar a equipos de seguridad
Más allá del “qué” y del “cuándo”, el caso de Cloudflare deja varios patrones que los responsables de ciberseguridad y resiliencia deberían tener en cuenta:
- Datos internos tratados como “de confianza”
El feature file se generaba a partir de datos internos y, en la práctica, se asumía que sería siempre válido. No existían salvaguardas suficientes para detectar que el contenido se había salido de los límites esperados antes de desplegarlo globalmente. - Caminos de error sin degradación controlada
El límite de 200 características estaba pensado como protección de rendimiento, pero el código reaccionaba con un panic al superarlo, en lugar de degradar la funcionalidad (por ejemplo, ignorando el exceso o activando una configuración mínima segura). - Acoplamiento fuerte entre un módulo avanzado y el plano de datos
El módulo de Bot Management, una capa avanzada de seguridad, terminó siendo un punto crítico cuya caída arrastró al proxy central. El diseño ideal habría sido poder desactivar o aislar temporalmente esa funcionalidad sin interrumpir el flujo de tráfico principal. - Kill switches globales insuficientes
La propia Cloudflare reconoce que necesita más interruptores globales que permitan apagar un módulo en segundos. En muchos entornos de seguridad, la capacidad de “desenchufar” una pieza defectuosa es tan importante como la de detectarla. - Riesgo de sobrecarga por observabilidad
En un entorno muy instrumentado, cada error genera más logs, más trazas y más consumo de CPU. Si no se controlan estos bucles, las herramientas pensadas para ayudar en un incidente pueden empeorarlo.
La respuesta de Cloudflare: endurecer el “core” de seguridad
Tras el incidente, la compañía ha enumerado una serie de acciones que ya tiene en marcha o en planificación:
- Validar los ficheros de configuración internos como si fueran entrada de usuario, incluyendo límites de tamaño, coherencia de contenido y mecanismos de rollback si algo se sale de lo previsto.
- Ampliar los mecanismos de apagado rápido (kill switches) para módulos como Bot Management, de modo que un error en una pieza no obligue a reiniciar el proxy completo.
- Limitar el impacto de volcados de memoria y reportes automáticos para que no puedan acaparar recursos críticos durante un pico de errores.
- Revisar los modos de fallo de todos los módulos del proxy (FL y FL2) para que, ante problemas de configuración o datos corruptos, el sistema pueda entrar en modo degradado pero funcional, en lugar de cortar el tráfico.
Para los lectores de un medio de seguridad, quizá la enseñanza más importante no está solo en lo que va a hacer Cloudflare, sino en lo que cada organización debería preguntarse:
- ¿Qué ocurre si mañana falla el proveedor que está en el centro de nuestro modelo Zero Trust?
- ¿Tenemos rutas alternativas si nuestra CDN, nuestro WAF o nuestro SSO quedan parcialmente indisponibles?
- ¿Tratamos nuestros propios datos internos de configuración con el mismo escepticismo con el que miramos el tráfico de fuera?
El apagón del 18 de noviembre no fue fruto de un atacante brillante, sino de una combinación de supuestos no revisados, acoplamientos fuertes y límites mal gestionados. Justo el tipo de errores que la ciberseguridad moderna, centrada en la resiliencia, lleva años advirtiendo que hay que anticipar.
Fuente: Apagón de Cloudflare