
Las organizaciones buscan respuestas directas a preguntas empresariales sin enfrentar la complejidad de redactar consultas SQL o navegar por paneles de inteligencia empresarial para extraer datos de almacenes estructurados. Este tipo de datos incluye tablas, bases de datos y almacenes de datos que siguen un esquema predefinido. La implementación de sistemas de consulta en lenguaje natural impulsados por modelos de lenguaje de gran escala (LLM) está revolucionando la interacción con los datos; por ejemplo, los usuarios pueden preguntar: “¿Cuál región tiene el mayor ingreso?” y recibir respuestas clarificadoras de inmediato.
Sin embargo, muchas organizaciones enfrentan el desafío de hacer que estos datos estructurados sean accesibles para usuarios no técnicos. Esto se debe a que muchos empleados carecen del conocimiento técnico necesario, como la habilidad para escribir consultas SQL, lo que los obliga a depender del equipo de BI o los científicos de datos para el análisis. Esta dependencia, además, ocasiona demoras en la obtención de información que afecta la toma de decisiones. A menudo, los paneles de control predefinidos limitan la exploración espontánea de los datos y los usuarios pueden no saber qué preguntas formuladas son posibles o dónde se encuentran los datos relevantes.
Las soluciones efectivas deben ofrecer una interfaz conversacional que permita a los empleados consultar fuentes de datos estructuradas sin necesidad de experiencia técnica. Esto incluye la capacidad de formular preguntas en un lenguaje cotidiano y recibir respuestas precisas y confiables, así como la generación automática de visualizaciones y explicaciones que comunican claramente los hallazgos. La integración de información de diferentes fuentes de datos, tanto estructuradas como no estructuradas, y la facilidad de integración con inversiones existentes son también esenciales.
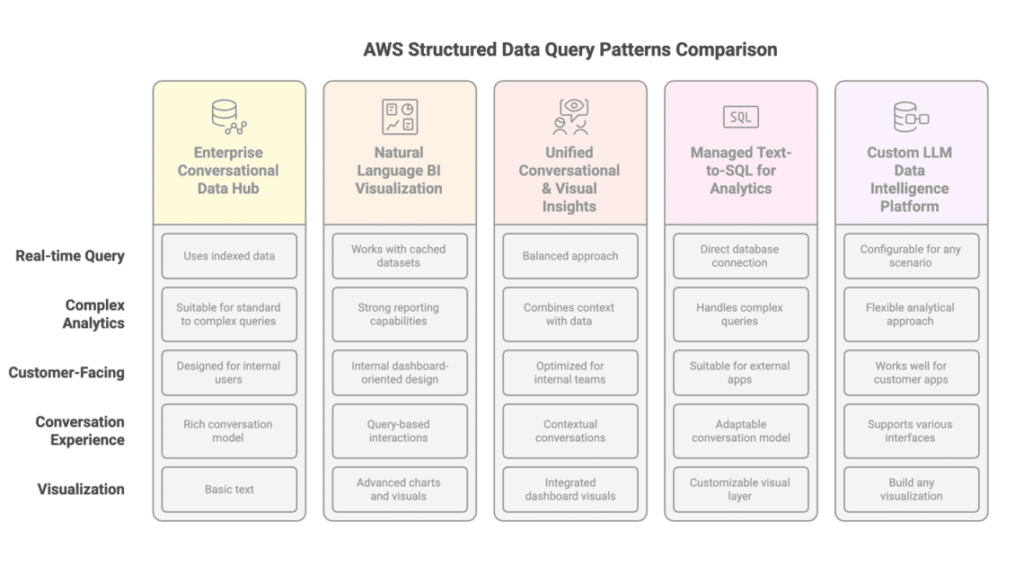
Desde esta perspectiva, varios patrones de consulta basados en LLM en AWS pueden ayudar a abordar estas necesidades. El primero de estos patrones utiliza Amazon Q Business, un asistente de inteligencia artificial que proporciona una interfaz de chat con fuentes de datos. Los usuarios pueden hacer preguntas y recibir respuestas sin necesidad de servicios intermedios, lo que facilita una experiencia unificada. Este enfoque es ideal para asistentes internos que deben responder a preguntas relativas a datos estructurados y no estructurados.
Otro patrón relevante mejora las herramientas de BI mediante la incorporación de capacidades de consulta en lenguaje natural. Amazon Q en QuickSight permite a los usuarios formular preguntas dentro de la interfaz y recibir respuestas visualizadas, eliminando la necesidad de codificación. Este modelo es idóneo para analistas y directivos que pueden hacer preguntas ad-hoc y obtener respuestas rápidas sin depender del equipo de análisis.
Además, la combinación de capacidades de visualización de BI con inteligencia conversacional crea una experiencia uniforme que entrega respuestas de diferentes tipos de datos en un mismo flujo conversacional. Esta integración es valiosa para empresas que buscan asistencia interna, donde la agilidad y la fluidez en la obtención de información se vuelven imprescindibles.
Para aquellos que buscan construir bases de conocimiento a partir de datos estructurados, Amazon Bedrock Knowledge Bases ofrece un módulo completamente gestionado de texto a SQL que facilita la recuperación de datos. Esto permite a las empresas desarrollar aplicaciones donde los usuarios pueden realizar consultas complejas sin necesidad de modelar el sistema, lo que reduce significativamente los obstáculos técnicos.
Finalmente, un patrón más flexible permite la construcción de soluciones personalizadas que convierten el lenguaje natural en SQL, ejecutando consultas en almacenes de datos y devolviendo resultados. Este enfoque permite a los desarrolladores adaptar las soluciones a necesidades específicas, lo que representa un gran paso hacia la personalización en la utilización de datos.
En conclusión, la elección del patrón adecuado dependerá de factores como la ubicación y características de los datos, el perfil del usuario y el modelo de interacción preferido, así como los recursos disponibles y los requisitos de gobernanza. Comprender estas alternativas puede permitir a las organizaciones arquitectar soluciones alineadas con sus objetivos empresariales y optimizar el uso de datos en sus procesos.
vía: AWS machine learning blog