
En la actualidad, las empresas procesan miles de documentos diariamente que contienen información empresarial crítica. Desde facturas y órdenes de compra hasta formularios y contratos, la localización y extracción precisa de campos específicos ha sido uno de los retos más complejos en los procesos de documentación. Aunque el reconocimiento óptico de caracteres (OCR) puede identificar el texto presente en un documento, determinar la ubicación de información específica ha requerido soluciones sofisticadas de visión por computadora.
La evolución en este campo demuestra la complejidad del desafío. Los primeros enfoques de detección de objetos, como YOLO (You Only Look Once), revolucionaron la detención de objetos al reformularla como un problema de regresión, permitiendo la detección en tiempo real. RetinaNet avanzó al abordar problemas de desequilibrio de clases mediante Focal Loss, y DETR presentó arquitecturas basadas en transformadores para minimizar los componentes diseñados manualmente. Sin embargo, estas soluciones compartían limitaciones comunes, incluyendo la necesidad de grandes volúmenes de datos de entrenamiento y arquitecturas de modelo complejas.
El surgimiento de modelos de lenguaje grandes multimodales (LLMs) marca un cambio paradigmático en el procesamiento de documentos. Estos modelos combinan una comprensión avanzada de la visión con capacidades de procesamiento de lenguaje natural, ofreciendo ventajas significativas. Entre sus características destacan la minimización del uso de arquitecturas especializadas de visión por computadora, capacidades de cero disparos sin necesidad de aprendizaje supervisado, interfaces en lenguaje natural para especificar tareas de ubicación, y una adaptación flexible a diferentes tipos de documentos.
Este artículo demuestra cómo utilizar modelos de base en Amazon Bedrock, específicamente Amazon Nova Pro, para lograr una alta precisión en la localización de campos dentro de documentos, simplificando drásticamente la implementación. Con estos modelos, es posible localizar e interpretar campos documentales con un esfuerzo mínimo, reduciendo así errores de procesamiento y la intervención manual.
La localización de información en documentos va más allá de la extracción tradicional de texto, ya que identifica la posición espacial precisa de la información. Esta habilidad permite operar en tareas críticas como chequeos automáticos de calidad y redacción de datos sensibles, fortaleciendo así las operaciones empresariales. Las metodologías tradicionales dependían de sistemas basados en reglas y modelos de visión por computadora especializados, que requerían extensos conjuntos de datos de entrenamiento y un mantenimiento continuo.
Los modelos multimodales con capacidades de localización que se ofrecen en Amazon Bedrock transforman este paradigma. En lugar de exigir arquitecturas de visión por computadora complejas y grandes volúmenes de datos de entrenamiento, estos LLMs pueden comprender tanto el diseño visual como el significado semántico de los documentos a través de interacciones en lenguaje natural. Al utilizar modelos con capacidad de localización, las organizaciones pueden implementar soluciones robustas con una sobrecarga técnica significativamente reducida.
El sistema de localización diseñado toma como entrada una imagen de documento y un texto como solicitado, procesándolo a través de modelos seleccionados en Amazon Bedrock. Esto devuelve las ubicaciones de los campos utilizando coordenadas absolutas o normalizadas. Se han implementado dos estrategias de solicitud distintas para la localización de campos: una basada en dimensiones de imagen y otra en un sistema de coordenadas escaladas, lo que ofrece mayor flexibilidad.
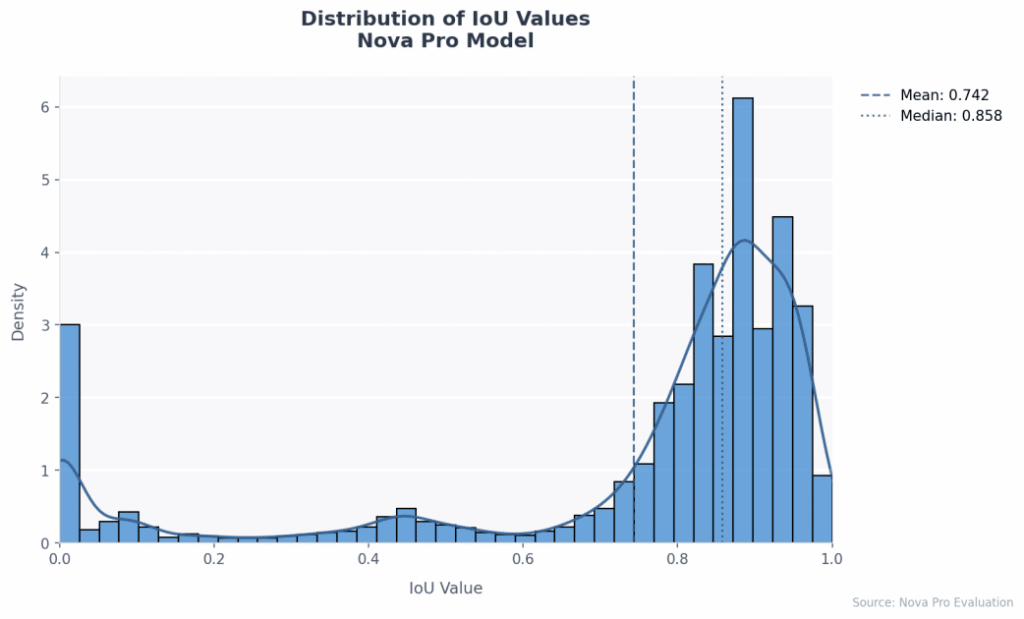
Los resultados de un estudio de benchmarking utilizando el dataset FATURA, que contiene 10,000 facturas individuales, muestran que los modelos pueden localizar y extraer campos con un esfuerzo de configuración mínimo, simplificando notablemente los flujos de trabajo tradicionales de visión por computadora. Amazon Nova Pro ha demostrado ser una excelente opción para el procesamiento de documentos empresariales, logrando una media de precisión (mAP) de 0.8305 con un rendimiento consistente en diversos tipos de documentos.
Este avance ofrece nuevas oportunidades para optimizar flujos de trabajo y una invitación para que las empresas comiencen a implementar soluciones innovadoras en su manejo documental.
vía: AWS machine learning blog