
Las organizaciones actuales enfrentan el desafío de procesar grandes volúmenes de datos de audio, desde llamadas de clientes y grabaciones de reuniones hasta podcasts y mensajes de voz, con el fin de desbloquear valiosos conocimientos. El Reconocimiento Automático de Habla (ASR, por sus siglas en inglés) es un paso fundamental en este proceso, ya que convierte el habla en texto para que se pueda realizar un análisis posterior. Sin embargo, aplicar ASR a gran escala es intensivo en recursos computacionales y costoso. Aquí es donde entra en juego la inferencia asíncrona en Amazon SageMaker AI.
Implementando modelos de ASR de última generación, como los modelos Parakeet de NVIDIA en SageMaker AI con puntos finales asíncronos, se pueden manejar archivos de audio grandes y cargas de trabajo por lotes de manera eficiente. Con la inferencia asíncrona, las solicitudes prolongadas pueden ser procesadas en segundo plano, facilitando la entrega de resultados en un momento posterior; asimismo, la capacidad de escalado automático se puede ajustar a cero cuando no hay trabajo, lo que permite gestionar picos de demanda sin bloquear otras tareas.
La suite de tecnologías de inteligencia artificial de voz de NVIDIA combina modelos de alto rendimiento con soluciones de implementación eficientes. El modelo Parakeet ASR representa capacidades de reconocimiento de voz de última generación, logrando una precisión de reconocimiento superior con bajos índices de error por palabra. Esta arquitectura utiliza un codificador Fast Conformer, que permite un procesamiento 2.4 veces más rápido que los Conformers estándar, manteniendo al mismo tiempo la exactitud.
Además, el NIM de NVIDIA es un conjunto de microservicios acelerados por GPU que sirven para construir aplicaciones personalizables de AI de voz. Con soporte para más de 36 idiomas, estos modelos son ideales para servicios al cliente, centros de contacto, accesibilidad y flujos de trabajo empresariales globales.
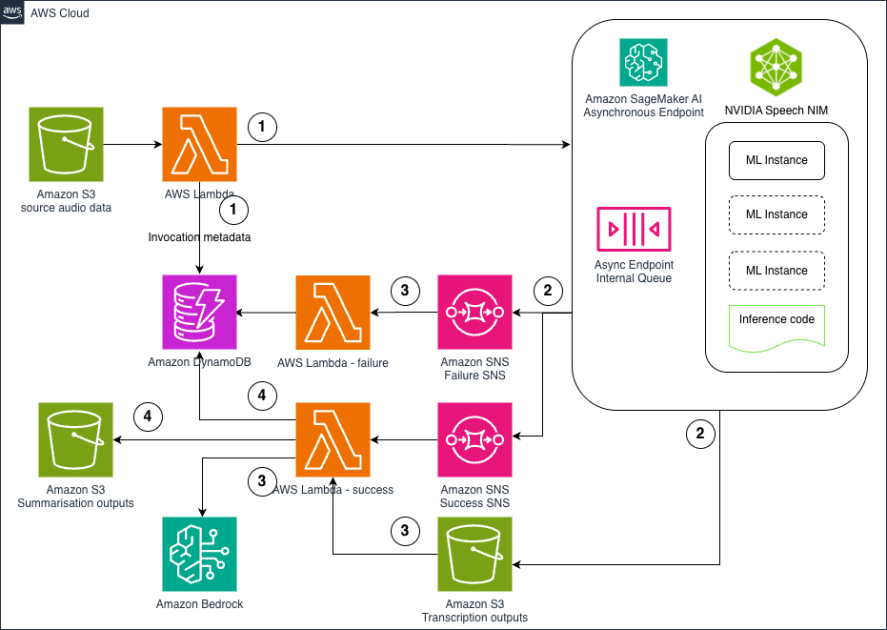
La implementación de esta tecnología permite una arquitectura integral de inferencia asíncrona diseñada específicamente para cargas de trabajo de ASR y resumido. Los componentes clave de esta arquitectura incluyen la ingestión de datos mediante la subida de archivos de audio a Amazon S3, el procesamiento de eventos a través de notificaciones de éxito y error mediante Amazon SNS, y el seguimiento en tiempo real del estado de trabajo mediante Amazon DynamoDB.
El flujo de trabajo sigue un patrón impulsado por eventos, donde al subir archivos de audio se activan funciones de Lambda que analizan los metadatos y crean registros de invocación. Una vez que el contenido es transcrito de manera exitosa, se envía a modelos de lenguaje de Amazon Bedrock para generar resúmenes, mientras el sistema maneja eficazmente los errores y puede reiniciar el procesamiento ante fallos temporales.
Esta solución tiene aplicaciones reales en diversas áreas, como el análisis del servicio al cliente, la transcripción y resumido de reuniones, y la generación de documentación legal y de cumplimiento normativo. La infraestructura de NVIDIA, combinada con la administración de servicios de AWS, crea un sistema automatizado y escalable para el procesamiento de contenido de audio, permitiendo a las organizaciones centrarse en obtener valor empresarial en lugar de manejar la complejidad de la infraestructura.
vía: AWS machine learning blog