
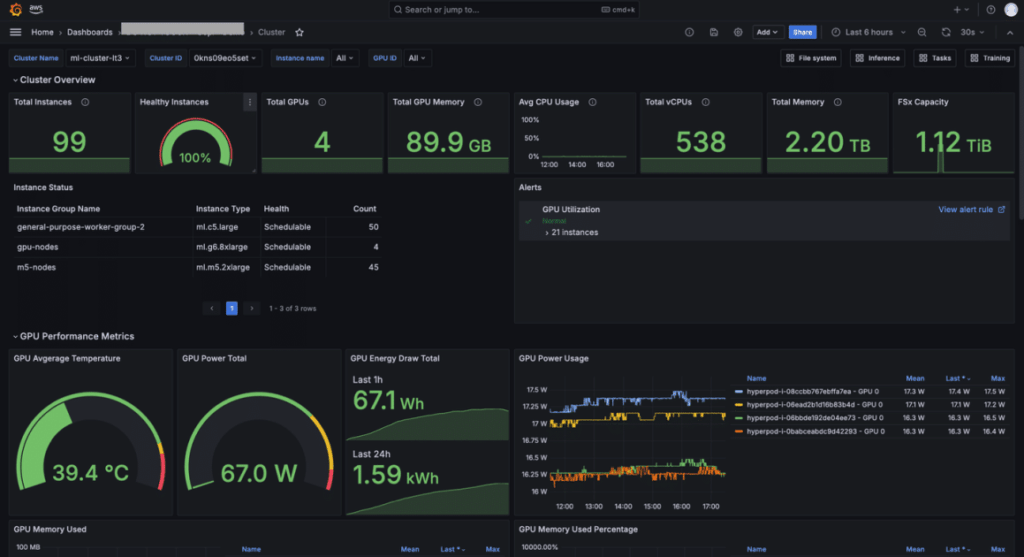
Amazon ha introducido una nueva característica en SageMaker HyperPod que promete cambiar las reglas del juego en el ámbito del desarrollo de modelos de inteligencia artificial. Esta actualización incluye un panel de control integral que ofrece una visión completa sobre las tareas de desarrollo de modelos fundamentales y los recursos del clúster, facilitando así la supervisión y optimización de los procesos.
Con la nueva solución de observabilidad, SageMaker HyperPod permite a los usuarios acceder a métricas clave a través de Amazon Managed Service for Prometheus, integrándolas en dashboards creados con Amazon Managed Grafana. Estos paneles están especialmente diseñados para el desarrollo de modelos fundamentales y proporcionan una cobertura detallada de la salud del hardware, la utilización de recursos y el rendimiento a nivel de tareas.
La instalación rápida de la funcionalidad se puede realizar mediante un complemento de Amazon Elastic Kubernetes Service (EKS) y permite consolidar datos de salud y rendimiento procedentes de varias fuentes, como NVIDIA DCGM y Kubernetes. Esto permite a los desarrolladores rastrear el rendimiento de las tareas de desarrollo de modelos en relación con los recursos del clúster, facilitando la identificación de problemas de hardware y la optimización de la utilización de GPU.
Una de las ventajas más notables de esta herramienta es su capacidad para ahorrar tiempo y recursos durante el desarrollo de modelos. Los científicos de datos y los ingenieros de aprendizaje automático pueden identificar rápidamente interrupciones en el entrenamiento y la inferencia, así como problemas en el rendimiento del hardware, lo que a su vez puede acelerar la comercialización de innovaciones en inteligencia artificial generativa.
El panel de control de SageMaker HyperPod es altamente configurable, permitiendo la importación de métricas PromQL adicionales y la personalización de los diseños en Grafana. Esto facilita una navegación intuitiva entre métricas y visualizaciones, lo que ayuda a los usuarios a diagnosticar problemas de manera más rápida y efectiva.
Además, se pueden establecer alertas personalizables que notifican a los administradores del clúster sobre cualquier problema de hardware, lo que permite una respuesta ágil ante situaciones críticas. Por ejemplo, se pueden configurar alertas para ser enviadas a plataformas como Amazon SNS o Slack, según las preferencias del equipo.
Esta nueva funcionalidad no solo mejora la visibilidad sobre el estado y el rendimiento del clúster, sino que también contribuye a optimizar la asignación de recursos al permitir a los administradores identificar patrones de uso ineficientes y ajustar las políticas de priorización.
Con la introducción de estas herramientas, Amazon reafirma su compromiso con la innovación en inteligencia artificial, ofreciendo a sus usuarios un camino más sencillo y eficiente para llevar sus modelos al mercado.
vía: AWS machine learning blog