
En el ámbito del entrenamiento de modelos de inteligencia artificial a gran escala, surgen desafíos significativos relacionados con la recuperación tras fallos y la monitorización. Las prácticas tradicionales requieren reiniciaciones completas de trabajos si un solo proceso de entrenamiento falla, lo que conlleva tiempos de inactividad adicionales y un aumento en los costos. A medida que se expanden los clústeres de entrenamiento, la identificación y resolución de problemas críticos como GPU atascadas e inestabilidades numéricas suelen requerir un código de monitoreo complejo y personalizado.
Como respuesta a estas necesidades, se presenta Amazon SageMaker HyperPod, una solución que acelera el desarrollo de modelos de IA utilizando cientos o miles de GPUs y que incorpora resiliencia integrada, lo que permite reducir el tiempo de entrenamiento de modelos hasta en un 40%. Este operador de entrenamiento de Amazon SageMaker HyperPod mejora la resiliencia del entrenamiento en cargas de trabajo de Kubernetes mediante técnicas de recuperación precisa y capacidades de monitoreo personalizables.
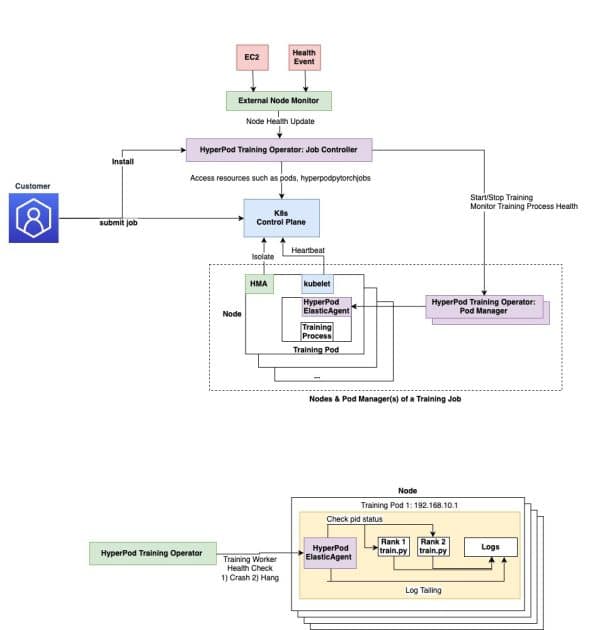
El operador de entrenamiento HyperPod utiliza componentes de resiliencia ante fallos y se implementa como un complemento de Amazon Elastic Kubernetes Service (EKS). Esta herramienta permite gestionar de manera eficiente el entrenamiento distribuido en grandes clústeres de GPU y proporciona definiciones de recursos personalizadas (CRD) necesarias en el clúster HyperPod. La arquitectura del operador sigue el patrón de operador de Kubernetes y se descompone en componentes clave como el controlador de trabajos y el gestor de pods.
Aprovechar el Amazon SageMaker HyperPod puede facilitar la recuperación granular de procesos. Esto quiere decir que, en lugar de reiniciar trabajos completos tras un fallo, el operador se centra en reiniciar solo los procesos de entrenamiento afectados, reduciendo los tiempos de recuperación de minutos a segundos, lo cual se traduce en una mejora significativa en la eficiencia operativa. Además, el operador integra un sistema de detección de nodos no saludables y permite reiniciar trabajos o procesos de entrenamiento debido a problemas de hardware, eliminando así la necesidad de soluciones de recuperación manuales.
Los beneficios adicionales incluyen un monitoreo centralizado del proceso de entrenamiento y la asignación eficiente de rangos, permitiendo una detección más efectiva de fallos. También es posible detectar trabajos en pausa y problemas de degradación de rendimiento a través de configuraciones YAML simples.
Para utilizar este operador, se proporciona una guía sobre cómo desplegar y gestionar cargas de trabajo de entrenamiento de machine learning mediante el Amazon SageMaker HyperPod. La instalación puede completarse en aproximadamente 30 a 45 minutos y requiere verificación de recursos y permisos necesarios en AWS.
El proceso incluye la instalación de componentes adicionales como cert-manager, la creación de un clúster de HyperPod, y la gestión de trabajos de entrenamiento basados en PyTorch a través de manifestos de Kubernetes.
Finalmente, es importante señalar que, al concluir un ciclo de entrenamiento, es recomendable limpiar los recursos creados para evitar cargos innecesarios. Esto incluye eliminar trabajos de HyperPod, imágenes de contenedores y complementos instalados.
Este enfoque innovador abordará los retos que enfrentan las organizaciones en el ámbito del desarrollo de modelos de inteligencia artificial, ofreciendo una solución robusta para los problemas comunes en el entrenamiento de modelos a gran escala. Al seguir las instrucciones de configuración y explorar la capacitación de ejemplo, las organizaciones pueden entender mejor cómo esta herramienta puede beneficiar sus usos específicos en el ámbito de la inteligencia artificial.
vía: AWS machine learning blog