
En un contexto de constante evolución en la infraestructura de inteligencia artificial, Amazon ha presentado mejoras significativas en su plataforma SageMaker HyperPod. Esta nueva funcionalidad permite a los usuarios gestionar cargas de trabajo concurrentes de manera más eficiente al adaptarse dinámicamente a la disponibilidad de recursos. Con la implementación de un sistema de entrenamiento elástico, las tareas de aprendizaje automático pueden escalar automáticamente, optimizando así la utilización de las unidades de procesamiento gráfico (GPU), reduciendo costos y acelerando el desarrollo de modelos.
Tradicionalmente, las cargas de trabajo de entrenamiento de modelos de IA se iniciaban con una configuración de recursos fija y, a pesar de los cambios en la demanda de capacidad, no podían aprovechar la potencia de cálculo disponible sin intervención manual. Esto llevaba a situaciones en las que un gran número de GPUs seguía desocupado, generando un desperdicio significativo de horas de cómputo y, por ende, costos operativos elevados. Las nuevas capacidades de SageMaker HyperPod resuelven este inconveniente permitiendo que los trabajos de entrenamiento escalen de forma dinámica, adaptándose a las fluctuaciones de recursos sin comprometer la calidad del entrenamiento.
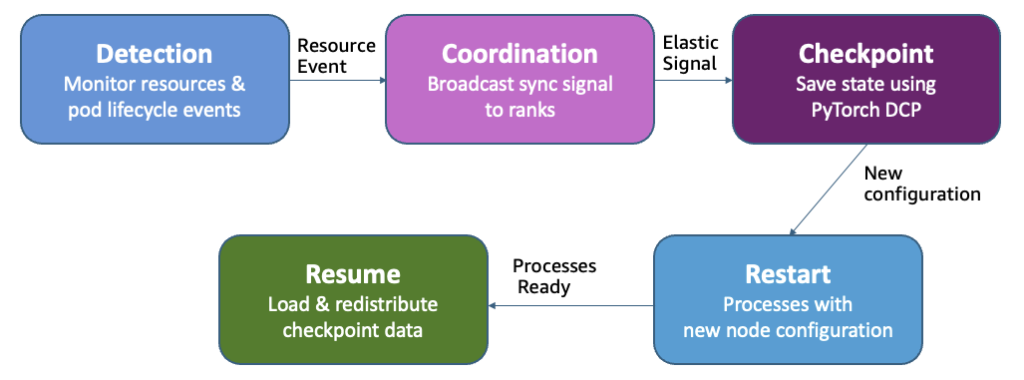
La complejidad técnica del escalado dinámico se ha abordado mediante la automatización de la orquestación de tareas, eliminando la necesidad de que los ingenieros de aprendizaje automático realicen ajustes manuales. SageMaker HyperPod gestiona eficazmente operaciones como la asignación de puntos de control y la reconfiguración de recursos en función de la disponibilidad. Esto ayuda a que los equipos puedan concentrarse en el desarrollo de modelos en lugar de en la gestión de la infraestructura.
Además, el sistema se ha diseñado para manejar solicitudes de recursos de manera más efectiva, priorizando tareas más críticas mientras mantiene la estabilidad de las operaciones de entrenamiento. Cuando un trabajo de mayor prioridad necesita recursos, SageMaker HyperPod ajusta la cantidad de réplicas en los trabajos de entrenamiento en lugar de detenerlos por completo, lo que permite una gestión más fluida y eficiente de los recursos.
Para respaldar esta funcionalidad, SageMaker HyperPod se integra con el plano de control de Kubernetes y el programador de recursos, tomando decisiones de escalado basadas en eventos de disponibilidad. Esto significa que, al detectar recursos libres, el sistema puede reaccionar casi instantáneamente, optimizando así tanto el tiempo de despliegue como la utilización de recursos.
Los beneficios son claros: una reducción significativa en el desperdicio de recursos y un incremento en la velocidad de desarrollo de modelos. Al eliminar los ciclos de reconfiguración manual, las organizaciones pueden disminuir los costos operativos y acortar los tiempos de lanzamiento al mercado de modelos de IA. SageMaker HyperPod se presenta, por tanto, como una solución integral para las necesidades cambiantes y dinámicas de las cargas de trabajo en inteligencia artificial.
vía: AWS machine learning blog