
La optimización de aplicaciones de inteligencia artificial generativa se basa en la personalización de modelos base a través de técnicas como la ingeniería de prompts, la recuperación de documentos (RAG), el preentrenamiento continuo y el ajuste fino. Un ajuste fino eficiente se logra mediante una gestión estratégica del hardware, el tiempo de entrenamiento, el volumen de datos y la calidad del modelo, con el fin de reducir las demandas de recursos y maximizar el valor.
Recientemente, se ha introducido un nuevo enfoque llamado Spectrum, diseñado para identificar las capas más informativas dentro de un modelo base. Este método permite ajustar finamente solo una parte del modelo, mejorando así la eficiencia del entrenamiento. Además, se han desarrollado diversas técnicas para afinar modelos de lenguaje de manera más eficiente, reduciendo tanto los recursos computacionales como el tiempo. Una de las técnicas más utilizadas es Quantized LoRA (QLoRA), que combina la adaptación de rango bajo con la cuantización del modelo original durante el entrenamiento. Aunque QLoRA ha mostrado resultados impresionantes, su implementación se realiza de manera uniforme en todo el modelo.
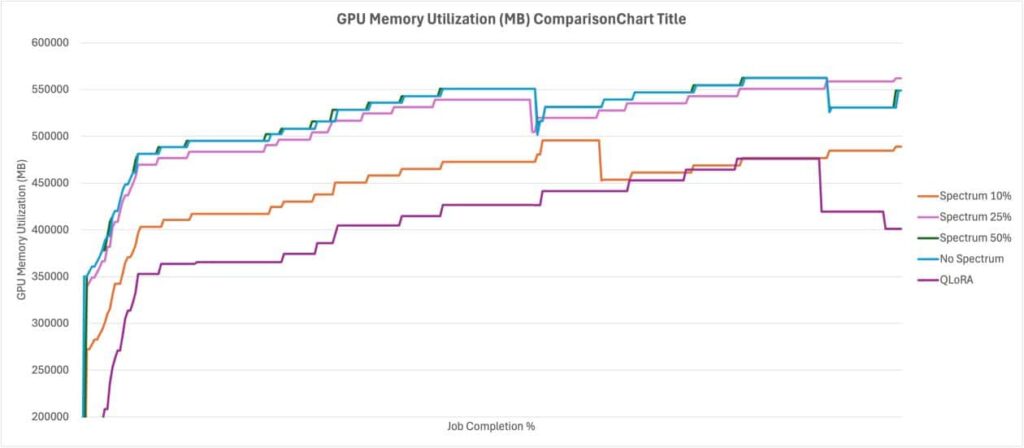
El uso de Spectrum permite optimizar el uso de recursos y acortar los tiempos de entrenamiento sin sacrificar la calidad. Este enfoque se puede implementar junto a trabajos de entrenamiento en Amazon SageMaker AI, donde se discutirá el tradeoff entre QLoRA y Spectrum, mostrando que, aunque QLoRA es más eficiente en recursos, Spectrum produce un rendimiento superior.
El funcionamiento del ajuste fino con Spectrum implica evaluar las matrices de peso a lo largo de las capas de un modelo base y calcular la Relación Señal/Ruido (SNR) capa por capa. En lugar de cuantificar todas las capas, Spectrum entrena selectivamente un subconjunto de capas en precisión total basado en su SNR y congela el resto del modelo. Se pueden realizar entrenamientos en FP16, BF16 o FP8, disponibles en las GPU más modernas.
Mediante el uso de la Teoría de Matrices Aleatorias y la distribución de Marchenko-Pastur, Spectrum distingue eficazmente entre señal y ruido. Basándose en un porcentaje configurable (por ejemplo, el 30%), identifica las capas más informativas de cada tipo para centrar el ajuste fino en ellas.
En un ejemplo práctico, se ilustrará el uso de Spectrum junto con trabajos de entrenamiento completamente gestionados en Amazon SageMaker para afinar el modelo Qwen3-8B. El ajuste fino con Spectrum consta de varios pasos clave, donde primero se descarga el modelo deseado, se realiza un análisis para determinar el SNR de cada capa y se crea un archivo que especifica el subconjunto de capas que se utilizarán en el trabajo de entrenamiento.
Antes de comenzar este proceso, es necesario tener una cuenta de AWS con permisos para crear recursos en SageMaker y configurar Amazon SageMaker Studio para ejecutar el código en un notebook Jupyter. Adicionalmente, se requiere clonar el repositorio spectrum y ejecutar los scripts de análisis para identificar las capas más influyentes.
Los trabajos de análisis generarán archivos que contienen un desglose completo del SNR de las capas analizadas, así como un archivo que lista las capas que deben permanecer sin congelar durante el entrenamiento. Con estos datos, se puede proceder a configurar el modelo para el ajuste fino, asegurando enfocar los recursos de entrenamiento en las capas más relevantes.
En resumen, con el uso de Spectrum, es posible reducir los requisitos de recursos para el ajuste fino de un modelo base, acortando el tiempo de entrenamiento y manteniendo un alto nivel de precisión. Esta innovación abre nuevas posibilidades en la optimización de modelos de inteligencia artificial, facilitando un enfoque más efectivo en las capas más críticas para el aprendizaje.
vía: AWS machine learning blog