
Las empresas están comenzando a adoptar modelos de lenguaje de gran escala (LLMs) a través de Amazon Bedrock para extraer conclusiones de sus fuentes de datos internas. Amazon Bedrock es un servicio totalmente gestionado que proporciona una selección de modelos de fundación de alto rendimiento de destacados proveedores de inteligencia artificial, como AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI y Amazon, a través de una única API. Este servicio también incluye un conjunto amplio de capacidades para construir aplicaciones de inteligencia artificial generativa, garantizando la seguridad, la privacidad y un enfoque en una inteligencia artificial responsable.
Las organizaciones que implementan sistemas de inteligencia artificial conversacional enfrentan un desafío común: aunque sus APIs son eficazmente rápidas para resolver preguntas específicas, las consultas más complejas, que requieren lógica de razonamiento y acción (ReAct), pueden tardar significativamente en procesarse, lo que afecta negativamente la experiencia del usuario. Este problema es especialmente crítico en industrias reguladas donde se exigen robustos requerimientos de seguridad. Por ejemplo, una organización global de servicios financieros con más de 1.5 billones de dólares en activos bajo gestión experimentó este inconveniente. A pesar de haber desplegado un sistema de inteligencia artificial conversacional que integraba múltiples LLMs y fuentes de datos, buscaban una solución que cumpliera con sus estrictos protocolos de seguridad sin comprometer la velocidad de respuesta para consultas complejas.
Para abordar este problema, AWS AppSync se presenta como una solución. Este servicio completamente gestionado permite a los desarrolladores construir APIs GraphQL sin servidor con capacidades en tiempo real. El enfoque aquí utiliza suscripciones de AWS AppSync junto con los puntos finales de streaming de Amazon Bedrock para entregar las respuestas de los LLM de manera incremental. Este artículo presenta un plan de implementación de grado empresarial que ayuda a las organizaciones en industrias reguladas a mantener el cumplimiento de seguridad al tiempo que optimiza la experiencia del usuario mediante la entrega de respuestas en tiempo real.
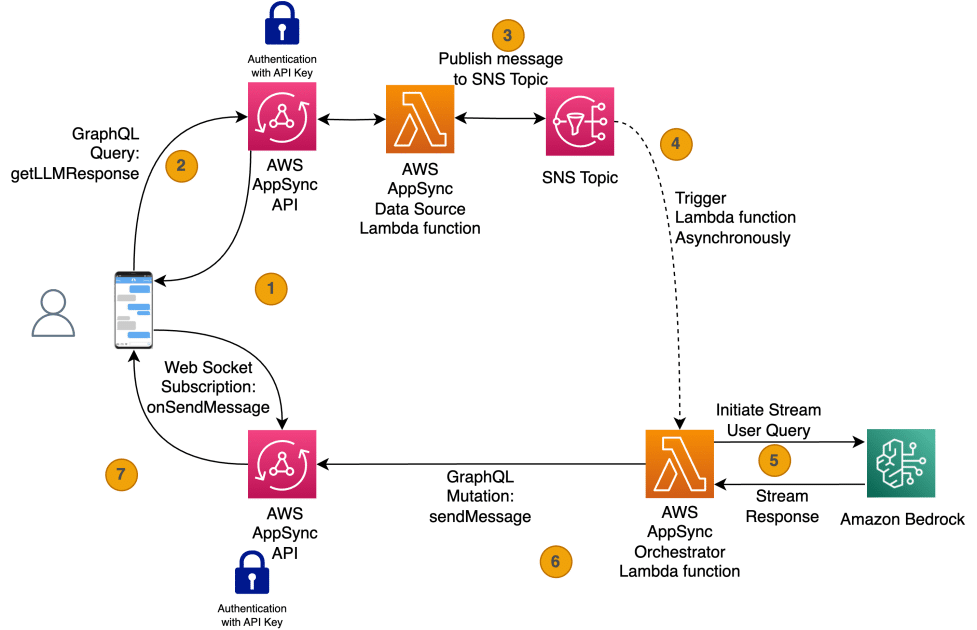
La solución utiliza AWS AppSync para iniciar el flujo de trabajo conversacional de forma asíncrona. Una función de AWS Lambda realiza la interacción con la API de streaming de Amazon Bedrock. A medida que el LLM genera tokens, estos se transmiten al front-end usando mutaciones y suscripciones de AWS AppSync.
La arquitectura de la solución implica varios pasos en el tratamiento de la solicitud del usuario, garantizando que este reciba respuestas en tiempo real de un LLM en Amazon Bedrock. Desde que el usuario carga la aplicación de interfaz de usuario, esta se suscribe a la conexión WebSocket para establecer la comunicación. Después de que el usuario formula una consulta, se invoca una función GraphQL que publica un evento en Amazon Simple Notification Service (SNS), y se envía un mensaje de confirmación al usuario, completando así el flujo sincrónico. Posteriormente, la función Lambda orquestadora se activa al recibir el evento SNS y comienza a comunicarse con la API de Amazon Bedrock para recibir los tokens en streaming, los cuales se envían al front-end en tiempo real.
La implementación de esta solución demuestra cómo la integración de Amazon Bedrock y AWS AppSync puede optimizar considerablemente los tiempos de respuesta en entornos empresariales. Con esta solución, una entidad del sector financiero logró reducir los tiempos de respuesta iniciales para consultas complejas de aproximadamente 10 segundos a entre 2 y 3 segundos, mejorando la interacción con los usuarios y brindando una experiencia más satisfactoria. Las empresas que implementen esta estrategia podrán beneficiarse al disminuir las tasas de abandono y mejorar el compromiso del usuario con sus aplicaciones.
vía: AWS machine learning blog