
En la actualidad, el fine-tuning multimodal se presenta como un enfoque poderoso para personalizar modelos de lenguaje y visión con gran capacidad de adaptación, optimizándolos para tareas específicas que involucran tanto información visual como textual. Aunque los modelos multimodales base ofrecen capacidades generales sorprendentes, en ocasiones se quedan cortos ante tareas visuales especializadas, contenido específico de dominio o requisitos de formato de salida. El fine-tuning permite superar estas limitaciones adaptando los modelos a datos y casos de uso concretos, mejorando drásticamente el rendimiento en las tareas relevantes para las empresas.
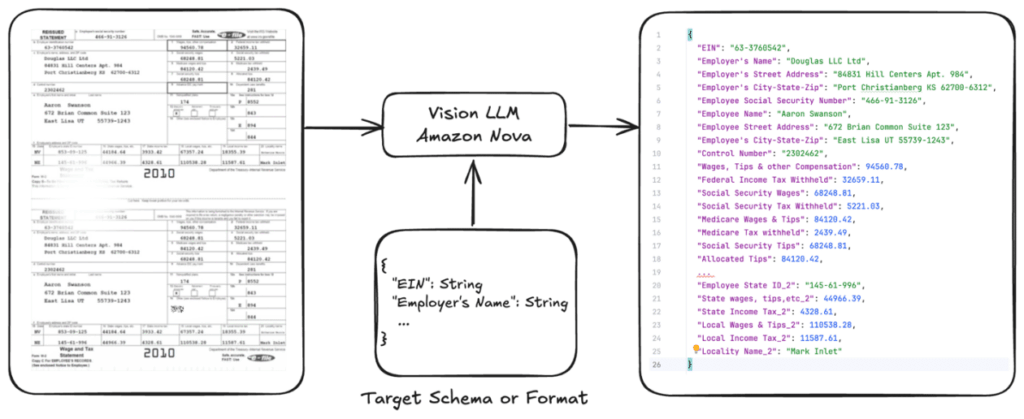
Una aplicación común de esta técnica es el procesamiento documental, que abarca la extracción de información estructurada de formatos complejos, como facturas, órdenes de compra, formularios, tablas o diagramas técnicos. Aunque los LLM (Modelos de Lenguaje de Gran Escala) estándar a menudo tienen dificultades con documentos especializados como formularios fiscales y solicitudes de préstamo, los modelos ajustados pueden aprender de variaciones en los datos y ofrecer una precisión significativamente mayor, además de reducir los costos de procesamiento.
Este artículo proporciona una guía práctica exhaustiva para ajustar Amazon Nova Lite para tareas de procesamiento de documentos, centrándose especialmente en la extracción de datos de formularios fiscales. Con el uso de un repositorio de código abierto en GitHub, se presenta un flujo de trabajo completo desde la preparación de datos hasta el despliegue del modelo. Gracias a Amazon Bedrock, que ofrece inferencia bajo demanda con precios por token, es posible beneficiarse de la mejora en la precisión mediante la personalización del modelo manteniendo una estructura de costos flexible.
El reto del procesamiento de documentos radica en extraer información estructurada de documentos de una o varias páginas para su utilización en sistemas posteriores. Entre las dificultades que enfrentan las empresas al automatizar flujos de trabajo se encuentran: la complejidad de los formatos, la diversidad de tipos de documentos, variaciones en la calidad de los datos, barreras lingüísticas y unos requisitos de precisión crítica, especialmente en la extracción de datos fiscales.
Las estrategias para el procesamiento inteligente de documentos utilizando LLMs se dividen en tres categorías principales: prompting sin ejemplos, prompting con ejemplos y fine-tuning. La opción de fine-tuning resulta especialmente útil para personalizar un LLM según tareas específicas facilitando la extracción o interpretación de datos relevantes.
Para crear un conjunto de datos anotados y seleccionar la técnica de personalización adecuada se deben tener en cuenta múltiples métodos. El fine-tuning supervisado es ideal cuando se dispone de datos etiquetados y se busca adaptar modelos para tareas particulares. Además, se pueden utilizar enfoques de destilación para crear modelos más pequeños y rápidos, transfiiriendo el conocimiento de un modelo más grande a uno más eficiente.
La implementación de estas técnicas dentro de Amazon Bedrock permite a los usuarios con habilidades básicas en ciencia de datos presentar trabajos de ajuste, completamente administrados en términos de capacidad. La promoción de modelos de Nova se lleva a cabo también a través de Amazon SageMaker, ofreciendo más opciones de personalización.
La preparación y calidad de los datos son cruciales para el éxito del fine-tuning. Se sugiere realizar un análisis del conjunto de datos, evaluar el modelo base y optimizar los prompts para alinearlos adecuadamente con las especificaciones del trabajo.
Una evaluación de modelos muestra mejoras significativas en la precisión y los resultados de F1 en múltiples categorías de campos tras la implementación del fine-tuning, destacando la capacidad de mantener una tasa de recuperación del 100% en el modelo ajustado.
Por último, Amazon Bedrock proporciona un modelo de costos transparente y predecible, haciendo que la solución sea coste-efectiva y fácil de escalar según las necesidades de procesamiento documental. Este enfoque elimina la necesidad de planificación de capacidad, permitiendo que las empresas optimicen su infraestructura al tiempo que mantienen un modelo de costes basado en el uso real.
vía: AWS machine learning blog