

La nueva medición de METR sobre Claude Mythos Preview ha colocado una pregunta incómoda en el centro de la ciberseguridad: qué ocurre cuando un modelo de Inteligencia Artificial deja de limitarse a sugerir código o resolver retos aislados y empieza a completar tareas técnicas que a un profesional humano le llevarían horas. La respuesta no apunta a una sustitución inmediata de los equipos de seguridad, pero sí a un cambio de escala que afecta tanto a defensores como a atacantes.
METR, una organización de investigación centrada en evaluar capacidades avanzadas de modelos de Inteligencia Artificial, actualizó el 8 de mayo de 2026 su página de “horizontes temporales” e incorporó una versión temprana de Claude Mythos Preview. En esa misma actualización incluyó una advertencia relevante: sus mediciones por encima de 16 horas ya no son fiables con el conjunto actual de tareas, lo que sugiere que los modelos más avanzados empiezan a presionar el límite de las pruebas disponibles.
Una forma distinta de medir el riesgo técnico
El “horizonte temporal” de METR no mide cuánto tiempo puede estar funcionando una IA sin intervención humana. Mide algo más útil para seguridad: la duración estimada de las tareas, calculada según el tiempo que tardaría un humano experto, que un agente puede resolver con una probabilidad determinada de éxito. En la práctica, una tarea de tres horas no significa que el modelo trabaje tres horas, sino que se enfrenta a un problema que a un profesional con experiencia y poco contexto previo le llevaría aproximadamente ese tiempo.
La gráfica compartida por METR sitúa a Claude Mythos Preview en torno a las tres horas con un criterio de éxito del 80 %. Traducido al lenguaje de un SOC, un equipo de respuesta a incidentes o un grupo de pentesting, hablamos de tareas de software y seguridad que ya no son triviales: depurar una librería pequeña, encadenar pasos técnicos, interpretar errores, probar hipótesis y llegar a una solución funcional con una fiabilidad alta.
El trabajo académico de METR que acompaña esta línea de investigación explica que la métrica busca relacionar el rendimiento de los modelos con capacidades humanas medibles. En su estudio, los autores combinaron tareas de RE-Bench, HCAST y una suite de acciones cortas de software, y observaron que el horizonte temporal al 50 % de éxito se había duplicado aproximadamente cada siete meses desde 2019. También destacaron que el avance parecía venir de una mayor fiabilidad, mejor adaptación a errores, mejor razonamiento lógico y más capacidad para usar herramientas.
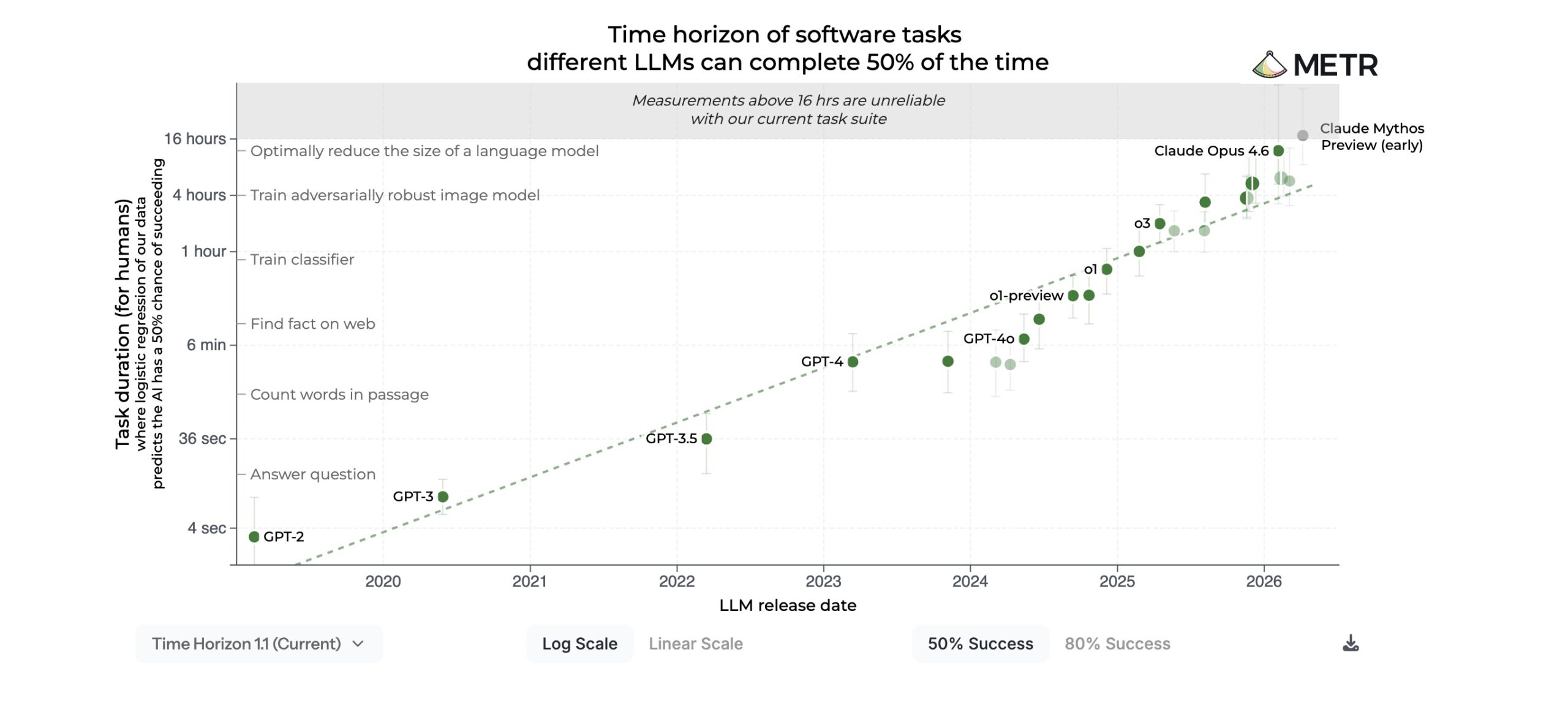
Para seguridad, esa combinación importa más que una puntuación aislada. Un atacante no necesita que un modelo sea perfecto; necesita que reduzca tiempo, coste y conocimiento necesario para encontrar una vulnerabilidad, probar un exploit, automatizar reconocimiento o adaptar un payload. Un defensor, por su parte, necesita justo lo contrario: usar esa misma capacidad para revisar código, detectar fallos antes de que se publiquen y acortar los ciclos de parcheo.
Mythos y la frontera entre defensa y ataque
Claude Mythos Preview no es un modelo disponible de forma general. Anthropic lo ha presentado dentro de Project Glasswing, una iniciativa orientada a reforzar la seguridad de software crítico con la participación de organizaciones como Amazon Web Services, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, la Linux Foundation, Microsoft, NVIDIA y Palo Alto Networks. Según Anthropic, el modelo se está usando como research preview con acceso limitado y ha identificado miles de vulnerabilidades de día cero en infraestructura crítica, una afirmación que conviene leer como parte de la comunicación pública de la compañía, pero que explica la atención que ha generado.
La propia Anthropic reconoce el carácter dual de estas capacidades. Un modelo capaz de comprender y modificar software complejo también puede encontrar y explotar sus debilidades. Por eso Project Glasswing está planteado como una ventaja inicial para defensores y mantenedores de software crítico, con créditos de uso y donaciones a organizaciones de seguridad open source. La compañía también ha indicado que no prevé poner Claude Mythos Preview a disposición general por ahora, y que su objetivo es desarrollar salvaguardas antes de desplegar modelos de esta clase a escala.
El AI Security Institute británico ha aportado una segunda lectura, más cercana al riesgo operativo. En sus evaluaciones, Mythos Preview mostró mejoras en retos capture-the-flag y en simulaciones de ataques multietapa. En tareas CTF de nivel experto, que ningún modelo completaba antes de abril de 2025 según el instituto, Mythos Preview alcanzó un 73 % de éxito.
El dato más llamativo llega de “The Last Ones”, una simulación de ataque a una red corporativa vulnerable con 32 pasos, desde el reconocimiento inicial hasta la toma completa de la red. AISI estima que ese escenario requeriría unas 20 horas de trabajo humano. Claude Mythos Preview fue el primer modelo en completarlo de principio a fin, con éxito en 3 de 10 intentos, y completó una media de 22 de los 32 pasos en todos sus intentos.
El riesgo real: sistemas débiles, velocidad y escala
La lectura responsable no es que Mythos pueda comprometer cualquier entorno empresarial bien defendido. El propio AI Security Institute advierte de que sus rangos de prueba son más sencillos que redes reales maduras: no incluyen defensores activos, herramientas defensivas ni penalizaciones por acciones que activarían alertas. Esa salvedad es importante para no convertir una evaluación de laboratorio en una profecía exagerada.
El problema es otro. Muchas organizaciones no tienen una postura de seguridad madura. Siguen arrastrando activos sin parchear, credenciales débiles, registros incompletos, servicios expuestos, segmentación deficiente y aplicaciones internas poco revisadas. En ese tipo de entornos, un agente capaz de ejecutar tareas técnicas de varias horas puede reducir mucho la barrera de entrada para ataques que antes exigían más experiencia.
AISI lo expresa con claridad: sus pruebas muestran que Mythos Preview puede explotar sistemas con una postura de seguridad débil, y es probable que aparezcan más modelos con capacidades similares. Por eso recomienda reforzar medidas básicas como la aplicación regular de actualizaciones, controles de acceso sólidos, configuración segura y logging completo.
La consecuencia para empresas y administraciones es práctica. La defensa frente a ataques asistidos por Inteligencia Artificial no empieza comprando una herramienta milagrosa, sino eliminando deuda de seguridad: inventario de activos, gestión de vulnerabilidades, hardening, autenticación multifactor, segmentación, copias de seguridad probadas, monitorización útil y capacidad real de respuesta. Lo nuevo es que el margen para aplazar esas tareas se estrecha.
También cambia el papel de los equipos de seguridad. Las organizaciones que adopten modelos de este tipo para defensa podrán revisar más código, probar más hipótesis y detectar antes fallos complejos. Las que no lo hagan tendrán que enfrentarse a adversarios que sí usarán automatización avanzada. La diferencia no estará solo en tener acceso a una IA potente, sino en saber integrarla con procesos, controles, revisión humana y gestión responsable de resultados.
Claude Mythos Preview no demuestra que la Inteligencia Artificial pueda reemplazar a un equipo de ciberseguridad. Sí muestra que las tareas que se pueden delegar a agentes empiezan a medirse en horas humanas, no en minutos. Para un sector acostumbrado a vivir con falta de talento, exceso de alertas y software cada vez más complejo, ese salto obliga a replantear prioridades. La seguridad básica deja de ser una recomendación prudente y pasa a ser una defensa mínima ante una generación de atacantes asistidos por modelos mucho más capaces.
Preguntas frecuentes
¿Qué ha medido METR sobre Claude Mythos Preview?
METR ha estimado el tipo de tareas técnicas que el modelo puede completar con distintas probabilidades de éxito, comparándolas con el tiempo que tardaría un humano experto.
¿Claude Mythos Preview puede lanzar ataques reales por sí solo?
En pruebas controladas, AISI observó que podía ejecutar ataques multietapa sobre redes vulnerables cuando recibía instrucciones y acceso. Eso no demuestra que pueda comprometer sistemas bien defendidos.
¿Por qué es importante para empresas con poca madurez de seguridad?
Porque los modelos capaces de automatizar tareas técnicas largas pueden reducir tiempo y conocimiento necesarios para explotar fallos ya existentes en sistemas mal parcheados o mal configurados.
¿Qué deberían hacer ahora los equipos de seguridad?
Priorizar inventario de activos, parcheo, control de accesos, configuración segura, segmentación, logging completo, copias probadas y capacidad de respuesta ante incidentes.