
La seguridad de una aplicación ya no se revisa solo con un escáner, una checklist y una auditoría puntual antes de publicar. Los nuevos modelos de IA agéntica, como Claude Fable 5, están empezando a cambiar la forma en que equipos de desarrollo y ciberseguridad analizan software real: no sustituyen al auditor, pero permiten repartir el trabajo entre agentes especializados que leen código, revisan flujos, contrastan evidencias, ejecutan herramientas y generan hallazgos de forma más continua.
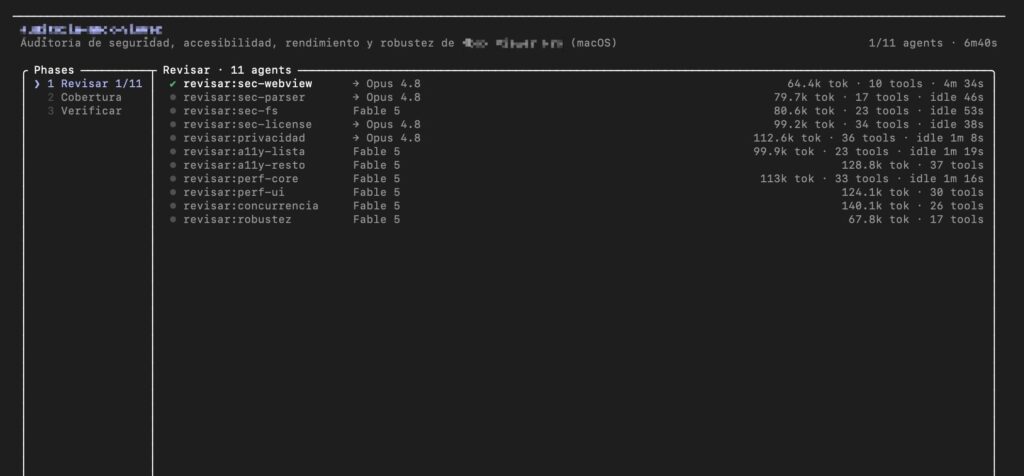
La imagen es bastante ilustrativa. Una auditoría de una aplicación macOS aparece dividida en fases, con 11 agentes trabajando sobre seguridad, accesibilidad, rendimiento y robustez. Hay tareas específicas para WebView, parser, sistema de archivos, licencias, privacidad, accesibilidad, interfaz, concurrencia y resiliencia. Unos agentes usan Opus 4.8, otros Fable 5. Cada uno consume tokens, invoca herramientas y avanza como una revisión técnica separada, pero coordinada.
Ese tipo de flujo explica por qué modelos como Fable 5 son relevantes para la ciberseguridad defensiva. No se trata de pedirle a una IA “encuéntrame vulnerabilidades” de forma genérica. La utilidad real aparece cuando el análisis se estructura por dominios, con permisos claros, repositorios controlados, reglas de actuación, límites de herramienta, trazabilidad y revisión humana.
De una auditoría lineal a un equipo de agentes
En una revisión tradicional, un equipo suele dividir el análisis por capas: seguridad de código, dependencias, permisos, privacidad, accesibilidad, rendimiento, pruebas de entrada, almacenamiento, sesiones, integración con servicios externos y comportamiento en error. El problema es que esa división consume tiempo y muchas veces se hace de forma incompleta por presión de plazos.
Los modelos agénticos permiten llevar esa lógica a una ejecución más paralela. Un agente puede revisar el uso de WebView y la exposición a contenido remoto. Otro puede centrarse en parsers y validación de entradas. Otro puede mirar permisos del sistema de archivos. Otro puede analizar licencias de dependencias. Otro puede comprobar privacidad, accesibilidad o rendimiento de la interfaz. El resultado no es una verdad automática, sino un mapa inicial mucho más amplio que el equipo humano puede verificar.
Este enfoque encaja con la evolución de Anthropic. Fable 5 y Mythos 5 se lanzaron el 9 de junio y comparten el mismo modelo base, aunque con perfiles muy distintos: Fable 5 llegó con salvaguardas fuertes para uso general, mientras que Mythos 5 se reservó para un grupo reducido de socios de Project Glasswing en trabajos defensivos de ciberseguridad.
| Área de revisión | Qué puede aportar un agente IA |
|---|---|
| Seguridad de WebView | Revisar configuración, límites de navegación y exposición a contenido remoto |
| Parsers y entradas | Buscar validaciones débiles, errores de formato y manejo inseguro de datos |
| Sistema de archivos | Comprobar permisos, rutas, almacenamiento local y tratamiento de ficheros |
| Licencias | Revisar dependencias, avisos legales y compatibilidad de componentes |
| Privacidad | Detectar datos sensibles, telemetría y tratamientos no documentados |
| Accesibilidad | Revisar etiquetas, navegación, contraste, foco y experiencia para usuarios asistidos |
| Rendimiento | Localizar cuellos de botella, uso excesivo de recursos y bloqueos de interfaz |
| Concurrencia | Revisar carreras, bloqueos, estados compartidos y fallos intermitentes |
| Robustez | Analizar errores, recuperación, validación y degradación ante fallos |
Para una aplicación de escritorio, móvil, web o backend, esta forma de trabajo tiene una ventaja evidente: cubre más superficie en menos tiempo. También obliga a documentar mejor qué se está revisando. Cada agente puede tener una misión concreta, herramientas permitidas y criterios de salida. Eso hace que la auditoría sea más repetible y menos dependiente de una revisión artesanal que cambia demasiado según quién la haga.
Fable 5: útil para defensa, pero diseñado con más límites
El caso de Fable 5 es interesante porque llega marcado por la seguridad. Anthropic tuvo que suspender temporalmente Fable 5 y Mythos 5 después de que el Gobierno de Estados Unidos aplicara controles de exportación el 12 de junio. La orden obligaba a restringir el acceso a ciudadanos extranjeros, dentro o fuera de Estados Unidos, y la compañía decidió cortar el acceso global al no poder verificar nacionalidades en tiempo real. Los controles se levantaron el 30 de junio y Fable 5 volvió a estar disponible globalmente desde el 1 de julio en Claude Platform, Claude.ai, Claude Code y Claude Cowork.
La interrupción se produjo tras un informe de investigadores de Amazon sobre una técnica para sortear salvaguardas de Fable 5 en tareas relacionadas con vulnerabilidades. Según Anthropic, en un caso el modelo produjo código que demostraba cómo podía explotarse una vulnerabilidad. La compañía sostiene, sin embargo, que sus pruebas internas mostraron que otros modelos menos capaces también podían identificar esas vulnerabilidades y producir la misma demostración, y que la técnica no reveló capacidades ofensivas exclusivas de Mythos 5.
La respuesta de Anthropic fue entrenar un clasificador de seguridad mejorado para bloquear esa técnica concreta en más del 99 % de los casos. Cuando una petición a Fable 5 se bloquea, el usuario recibe aviso y la solicitud se redirige a Opus 4.8. La contrapartida es conocida por cualquier equipo que haya trabajado con filtros de seguridad: aumentan los falsos positivos en tareas legítimas de programación, depuración y análisis defensivo.
Esto define bien el papel de Fable 5 en auditorías de aplicaciones. Puede ser muy útil para revisión defensiva, análisis de código, documentación de hallazgos, priorización y propuestas de mitigación. Pero no está pensado para operar sin límites ni para facilitar cadenas ofensivas. Anthropic explica que Fable 5 se lanzó con su margen de seguridad más amplio hasta la fecha, de modo que muchas solicitudes ambiguas se bloquean aunque puedan ser benignas.
Qué mejora en el desarrollo seguro
En un equipo de desarrollo, los modelos de este tipo aportan valor en tres momentos. El primero es antes de publicar una versión. Pueden revisar cambios, detectar patrones de riesgo, generar preguntas para el equipo y señalar zonas que merecen pruebas manuales. El segundo es durante el mantenimiento. Una aplicación madura acumula deuda técnica, permisos heredados, dependencias viejas y decisiones de arquitectura que ya nadie recuerda. Un agente puede volver sobre esas zonas con paciencia y contexto. El tercero es después de un incidente o de un informe externo: puede ayudar a reproducir, entender impacto, buscar variantes y preparar correcciones revisables.
La diferencia frente a un escáner clásico está en la capacidad de razonamiento contextual. Un SAST puede marcar una función sospechosa. Un agente puede leer cómo se usa, revisar el flujo que la llama, buscar documentación asociada, comparar con patrones del proyecto y generar una hipótesis más útil para el auditor. Eso no elimina falsos positivos, pero puede reducir el tiempo hasta llegar a una conclusión.
También ayuda en áreas que la seguridad suele dejar en segundo plano. Accesibilidad, rendimiento, privacidad y robustez rara vez se tratan como parte de una misma auditoría, aunque afectan directamente al riesgo operativo. Una app que se bloquea, consume recursos de forma excesiva, no informa bien de permisos o gestiona mal estados concurrentes puede generar problemas reales aunque no haya una vulnerabilidad clásica.
Para medios de ciberseguridad, el mensaje importante es que la IA agéntica no se limita al pentesting. Su mayor valor puede estar en la mejora continua de software: revisar lo que cambia, explicar riesgos, proponer pruebas, ayudar a escribir tickets y convertir hallazgos en trabajo accionable para ingeniería.
El reto: control, aislamiento y evidencia
El entusiasmo no debe ocultar los límites. Una auditoría con agentes IA necesita reglas. El código debe analizarse en entornos controlados. Las herramientas peligrosas deben requerir confirmación humana. Los secretos no deben exponerse al modelo ni a contenedores de prueba. Las acciones deben quedar registradas. Las recomendaciones deben contrastarse con pruebas, no aceptarse por autoridad.
Este punto es especialmente importante con modelos capaces de usar terminales, navegadores o herramientas. La autonomía sin trazabilidad no es una mejora de seguridad; es otra fuente de riesgo. Una buena arquitectura de auditoría debe separar lectura, ejecución, cambios, pruebas y publicación. El agente puede sugerir o preparar, pero el paso a producción tiene que seguir en manos del equipo responsable.
Anthropic también ha propuesto un marco común para medir la gravedad de jailbreaks, junto con Amazon, Microsoft, Google y otros socios de Glasswing. La idea es puntuar cada técnica según ganancia de capacidad, amplitud, facilidad para convertirla en ataque y descubribilidad. Es un intento de dar a la industria un lenguaje común para diferenciar entre fallos menores de salvaguarda y evasiones realmente peligrosas.
Ese tipo de marco será necesario si los modelos van a entrar en auditorías reales. Los equipos necesitan saber qué capacidades pueden usar, qué peticiones se bloquearán, qué riesgos existen y cómo se documentan las excepciones. Sin esa claridad, la IA en ciberseguridad puede quedar atrapada entre dos extremos: herramientas demasiado bloqueadas para ser útiles o modelos demasiado abiertos para ser seguros.
Hacia auditorías continuas de software
La imagen de varios agentes revisando una aplicación macOS anticipa un cambio más amplio. Las auditorías dejarán de ser documentos estáticos hechos una vez al año y se parecerán más a pipelines de revisión continua. Cada cambio relevante podrá activar agentes especializados. Cada release podrá producir un informe de seguridad, privacidad, accesibilidad y rendimiento. Cada hallazgo podrá convertirse en una prueba, un ticket o una propuesta de corrección.
No sustituye a SAST, DAST, revisión manual, threat modeling o pentesting externo. Los complementa. La IA puede hacer más barato repetir revisiones, mirar áreas que antes quedaban fuera y acelerar el paso de “hemos encontrado algo” a “sabemos dónde está, cómo afecta y qué deberíamos cambiar”.
Fable 5 representa bien esta etapa. Es lo bastante potente para trabajar como copiloto avanzado en análisis defensivo, pero llega con salvaguardas estrictas y con una historia reciente que recuerda que las capacidades de ciberseguridad en IA ya son un asunto regulatorio, no solo técnico.
Para los equipos de seguridad, la oportunidad está en usar estos modelos para mejorar aplicaciones de todo tipo: apps de escritorio, SaaS, APIs, móviles, paneles internos, herramientas industriales o software corporativo. La condición es tratarlos como parte de un proceso de ingeniería, no como un oráculo.
La IA puede leer mucho, comparar mucho y no cansarse. El criterio, la autorización y la responsabilidad siguen siendo humanos.
Preguntas frecuentes
¿Qué puede aportar Fable 5 a una auditoría de aplicaciones?
Puede ayudar a revisar código, flujos, permisos, privacidad, accesibilidad, rendimiento y robustez mediante agentes especializados, siempre dentro de un proceso defensivo y supervisado.
¿Fable 5 sirve para pentesting ofensivo?
Anthropic lo presenta como un modelo con salvaguardas fuertes para uso general. Para ciberseguridad defensiva avanzada, la compañía diferencia Fable 5 de Mythos 5, que tiene menos salvaguardas y acceso mucho más restringido.
¿Puede una IA sustituir a un auditor de seguridad?
No. Puede acelerar revisiones, generar hipótesis, preparar informes y sugerir mitigaciones, pero los hallazgos deben verificarse con pruebas, criterio técnico y revisión humana.
¿Qué riesgos tiene usar agentes IA en ciberseguridad?
Los principales riesgos son falsos positivos, exposición de secretos, acciones no autorizadas, uso de herramientas peligrosas sin control y confianza excesiva en resultados no verificados.
¿Cómo debería implantarse en una empresa?
Con repositorios controlados, entornos aislados, permisos mínimos, registros de actividad, aprobaciones humanas para acciones sensibles y validación de hallazgos mediante pruebas reproducibles.